GASNet 2004 Performance (historical)
The results on this page are VERY old, demonstrating GASNet performance on long-outdated/decomissioned systems, and only shown here for historical interest.
The following graphs show performance of GASNet release v1.4, measured 11/2004.
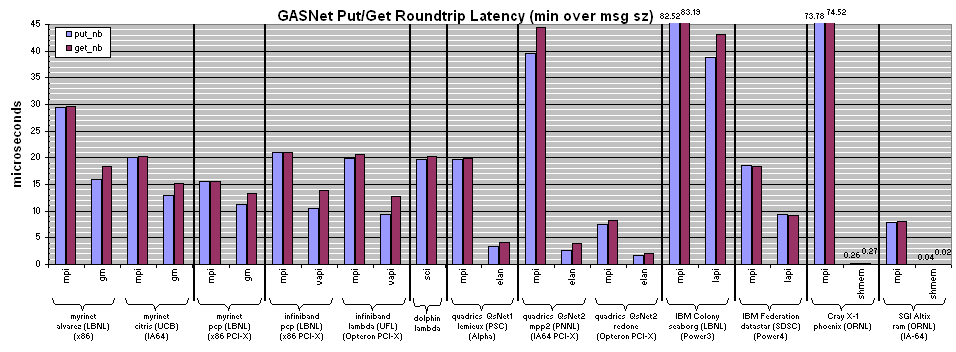
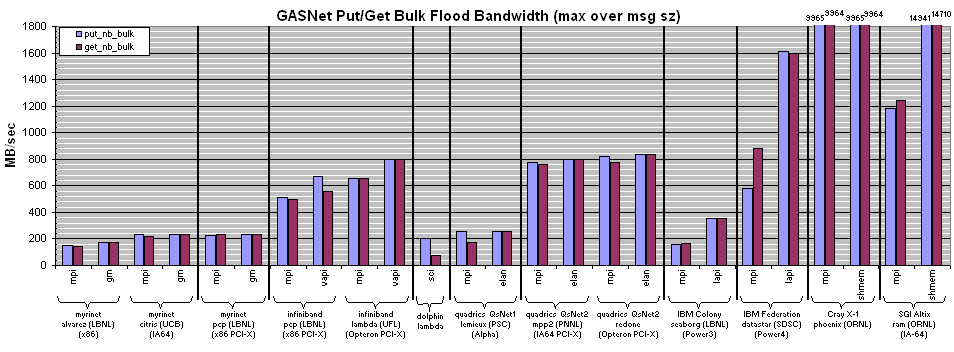
Summary: GASNet performance across many networks, machines and conduits
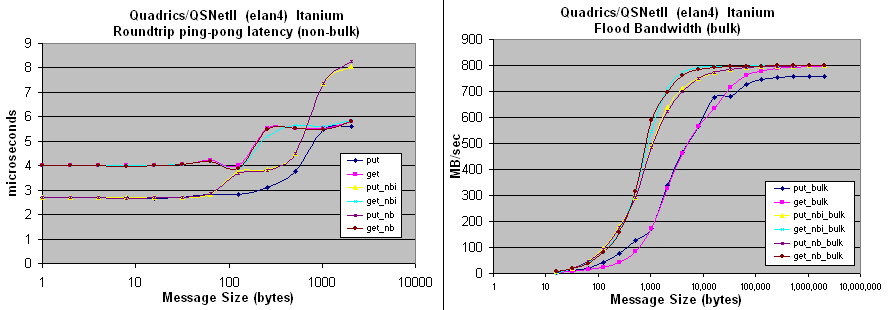
elan-conduit: on 'MPP2' at PNNL
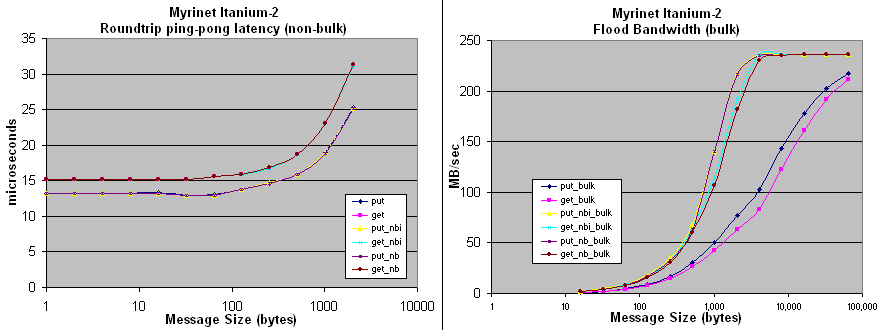
1.5 GHz Intel Itanium-2, Quadrics QsNet2/Elan4 interconnect, 8GB main mem
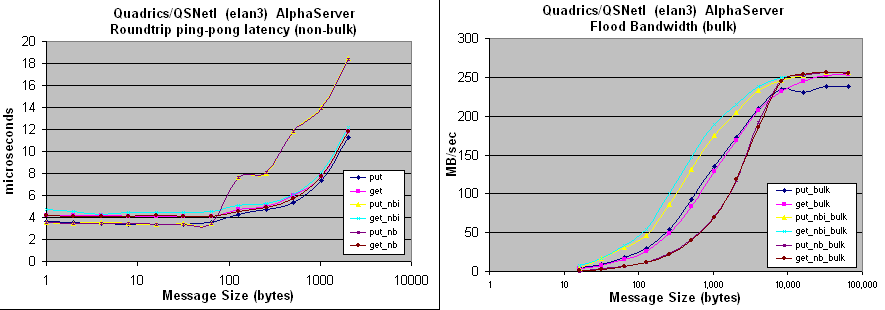
elan-conduit: on the Lemieux TSC at the Pittsburgh Supercomputing Center
Compaq Alphaserver SC, ES45 Elan3, double-rail (only tested w/single)
750-node, 4-way 1GHz Alpha, 4GB, libelan1.3, OSF 5.1
gm-conduit: on the Berkeley CITRIS
cluster
Itanium-2 Linux Cluster, LANai10.0 PCI-X, GM 2.0.8
64-node, 2-way 1.3 GHz Itanium-2, 4GB
PCI-X bus bandwidth: 482 MB/sec read, 501 MB/sec read
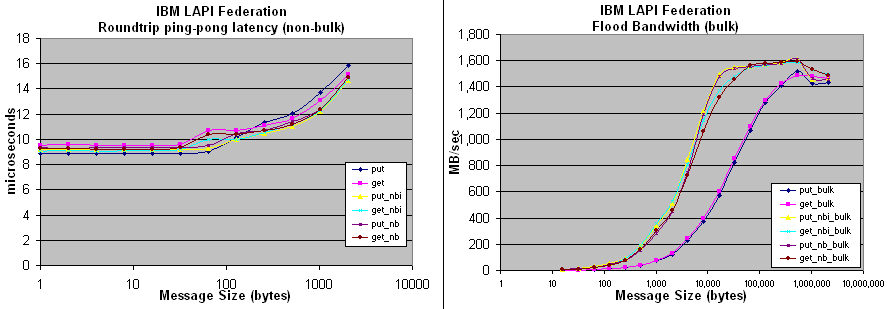
lapi-conduit: on the NPACI/SDSC 'DataStar' IBM SP
IBM Federation Interconnect, LAPI v.2.3.2.1, 8-way 1.5GHz Power4, 16GB main mem
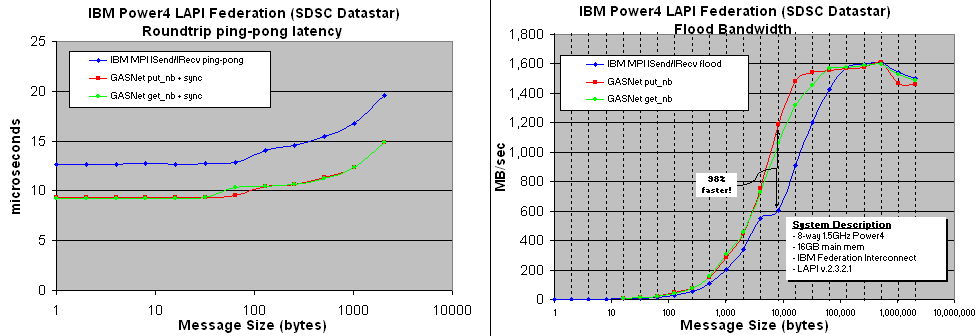
 Comparing GASNet lapi-conduit and IBM MPI back-to-back on the same Power4/Federation hardware:
Comparing GASNet lapi-conduit and IBM MPI back-to-back on the same Power4/Federation hardware:
Both GASNet and IBM MPI are built on top of the IBM LAPI interface.
GASNet consistently and significantly outperforms IBM MPI, because GASNet's lightweight semantics are
a closer match to the operations exposed in the LAPI interface, and eliminate MPI's tag/communicator
matching and message ordering enforcement that generally impose additional copies and CPU overheads.
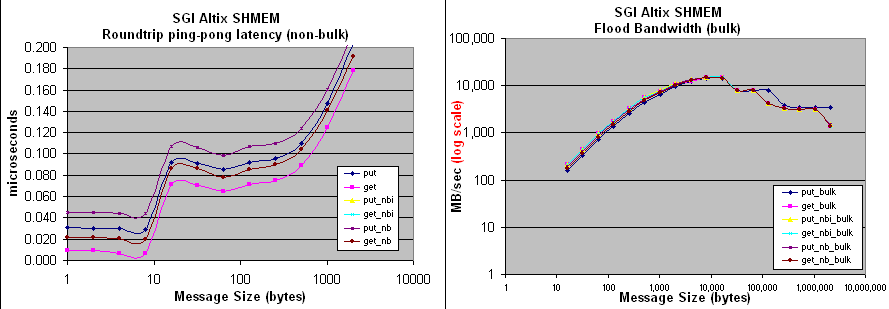
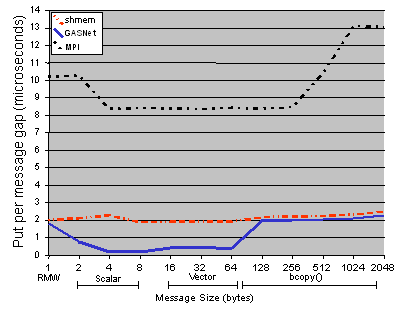
shmem-conduit: on the Altix 3000 'Ram' at ORNL
1.5 GHz Intel Itanium-2, 6MB L3, 256KB L2, 32K L1, 2 TB system memory (8GB/node)
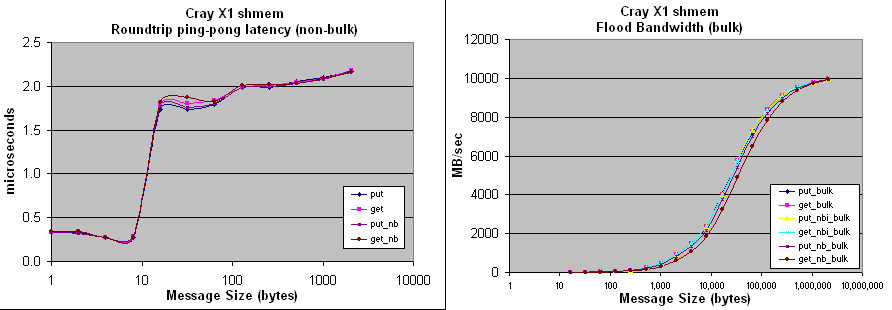
shmem-conduit: on the Cray X1 'Phoenix' at ORNL
512 MSPs, 2MB cache per MSP, 16 GB per node
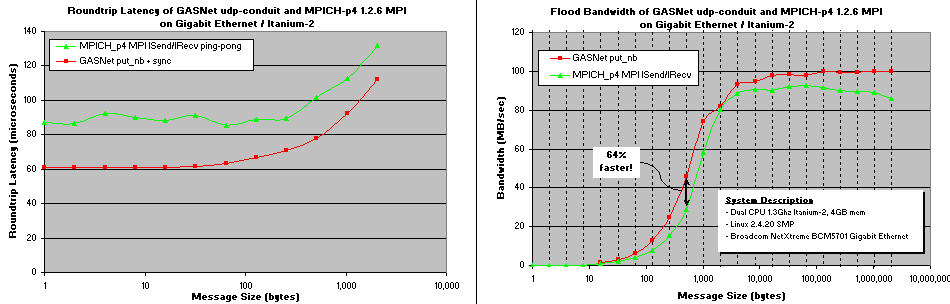
udp-conduit vs MPICH_p4 MPI:
Comparing GASNet udp-conduit and MPICH_p4 MPI back-to-back on the same Gigabit Ethernet hardware:
1.3 GHz Dual Itanium-2, 4 GB, Broadcom NetXtreme BCM5701 Gigabit Ethernet, Linux 2.4.20, PCI-X
PCI-X bus bandwidth: 482 MB/sec read, 501 MB/sec read
Both layers pay a high latency cost due to kernel crossings and
store-and-forward routing required by Ethernet (which generally make Ethernet an unsuitable
network hardware for parallel scientific computing).
However, GASNet consistently and significantly outperforms MPICH_p4.
MPICH-p4 is built on TCP, a non-scalable and heavyweight connection-based protocol that often imposes
extra copies and includes reliability and ordering protocols designed for streaming applications.
GASNet builds its operations directly on UDP, a light-weight unordered
datagram protocol which is the lowest-level protocol portably available in the TCP/IP stack. UDP is an
unreliable protocol, so GASNet achieves reliability using a protocol which is designed
and tuned specifically for the needs of HPC (see AMUDP).
GASNet semantics never guarantee ordering, and the implementation gains performance by not providing it.
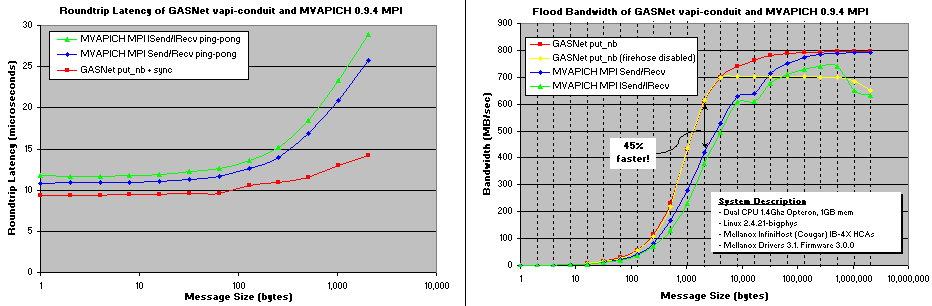
vapi-conduit vs MVAPICH MPI:
Comparing GASNet vapi-conduit and OSU MVAPICH MPI back-to-back on the same Infiniband hardware:
Dual 1.4Ghz Opteron, 1GB main memory mem
Linux 2.4.21-bigphys, Mellanox InfiniHost (Cougar) IB-4X HCAs, Mellanox Drivers 3.1, Firmware 3.0.0
MVAPICH numbers are from their own unmodified tester, re-normalized to MB=2^20 bandwidth bytes and full round-trip latency.
GASNet numbers are from the GASNet testsmall and testlarge benchmarks.
GASNet consistently and significantly outperforms MVAPICH because the GASNet one-sided put/get semantics are
fundamentally a better match for the capabilities of the underlying RDMA hardware
than MPI's two-sided message passing semantics. GASNet's put/gets turn into simple, fully one-sided
RDMA operations in the common case, and therefore reap the hardware peak performance, whereas
MPI pays in performance for enforcing MPI's ordering and tag matching semantics.
Back to the GASNet home page


