GASNet 2016 Performance (historical)
The results on this page are VERY old, demonstrating GASNet performance on now-outdated/decomissioned systems, and only shown here for historical interest.
The following graphs show performance examples of GASNet release v1.26.4, measured 8/2016.
Test Methodology:
All tests use two physical nodes, with one core injecting communication operations to the remote node and all other cores idle.
Hardware configuration details are provided in each section.
-
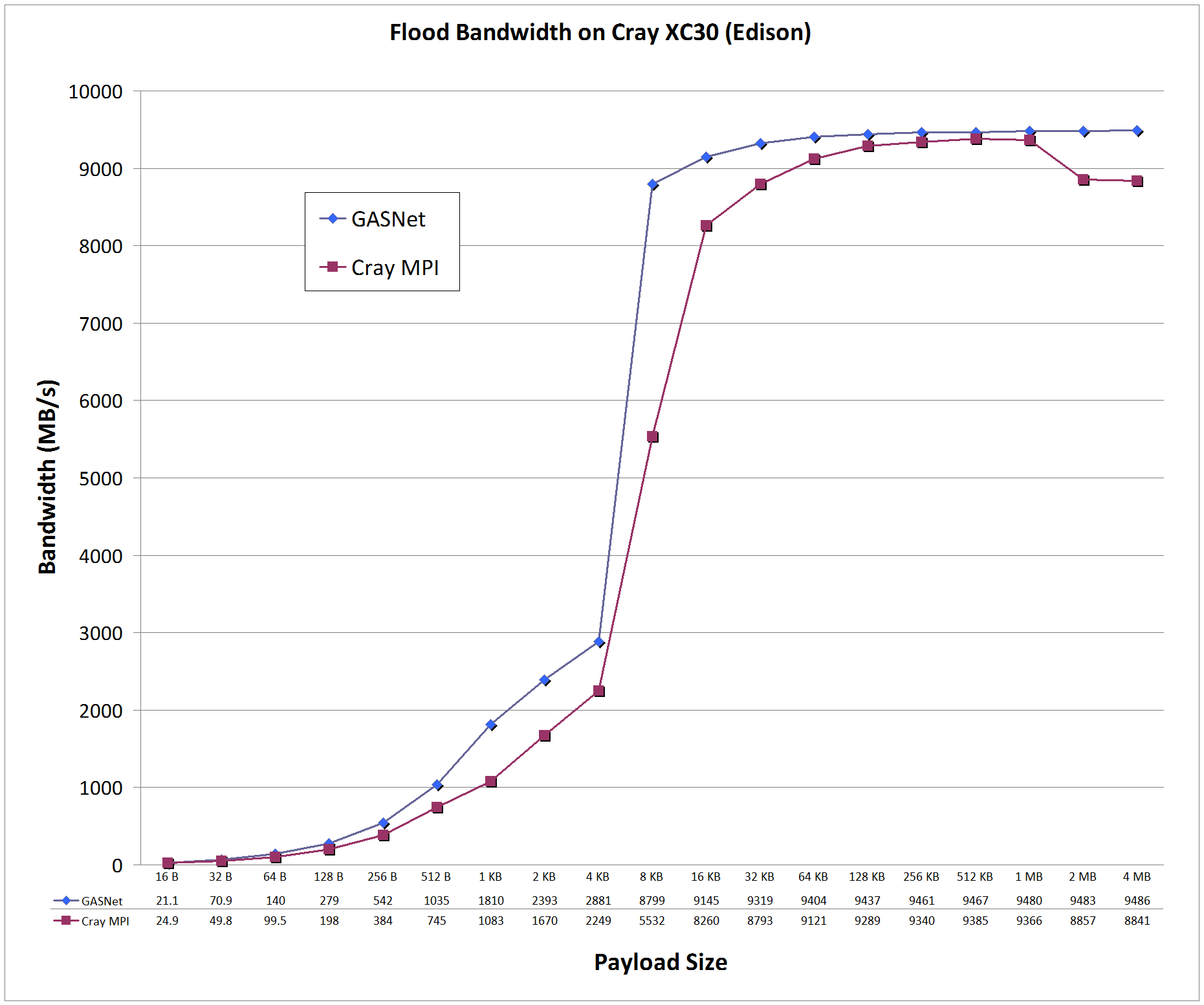
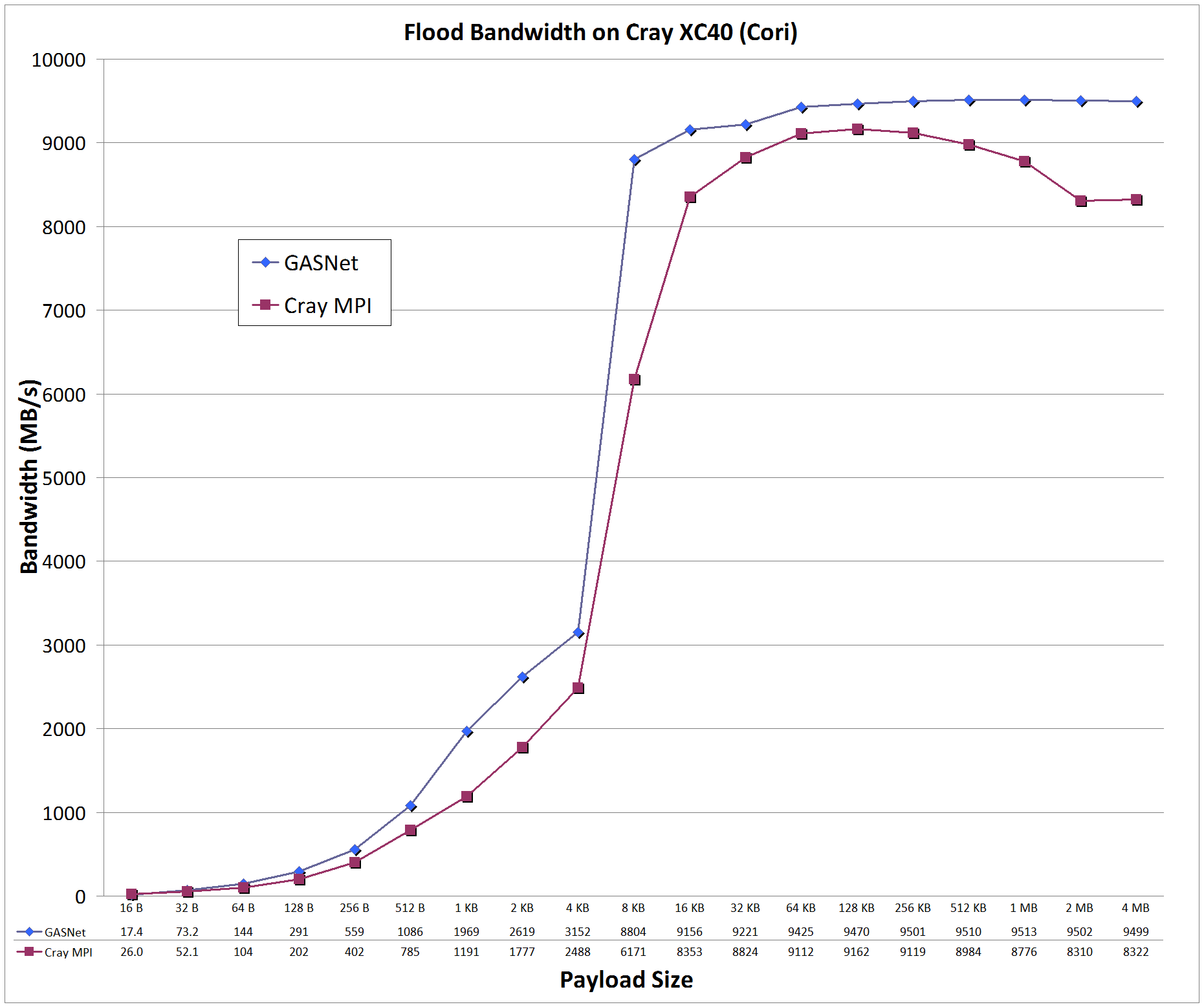
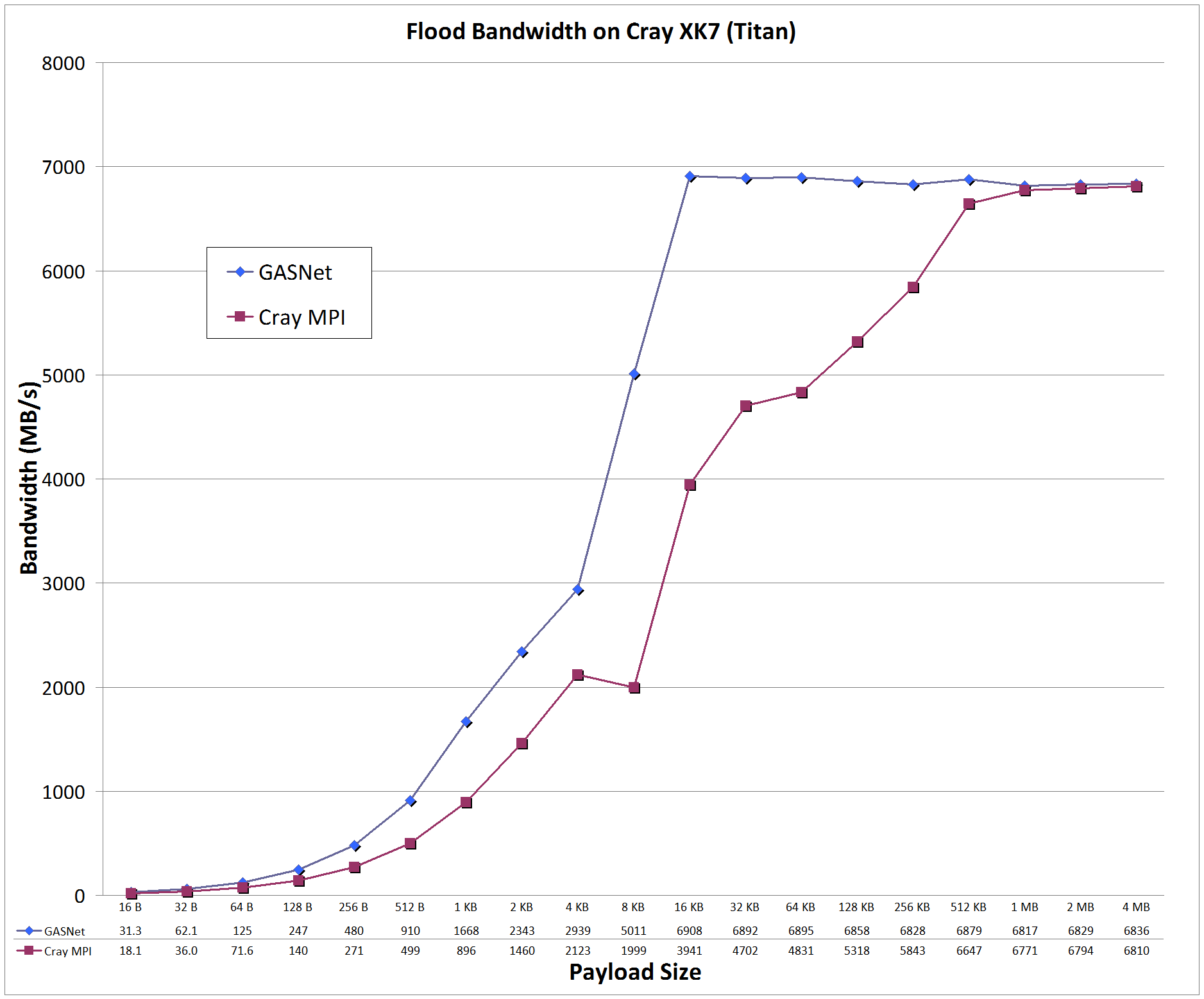
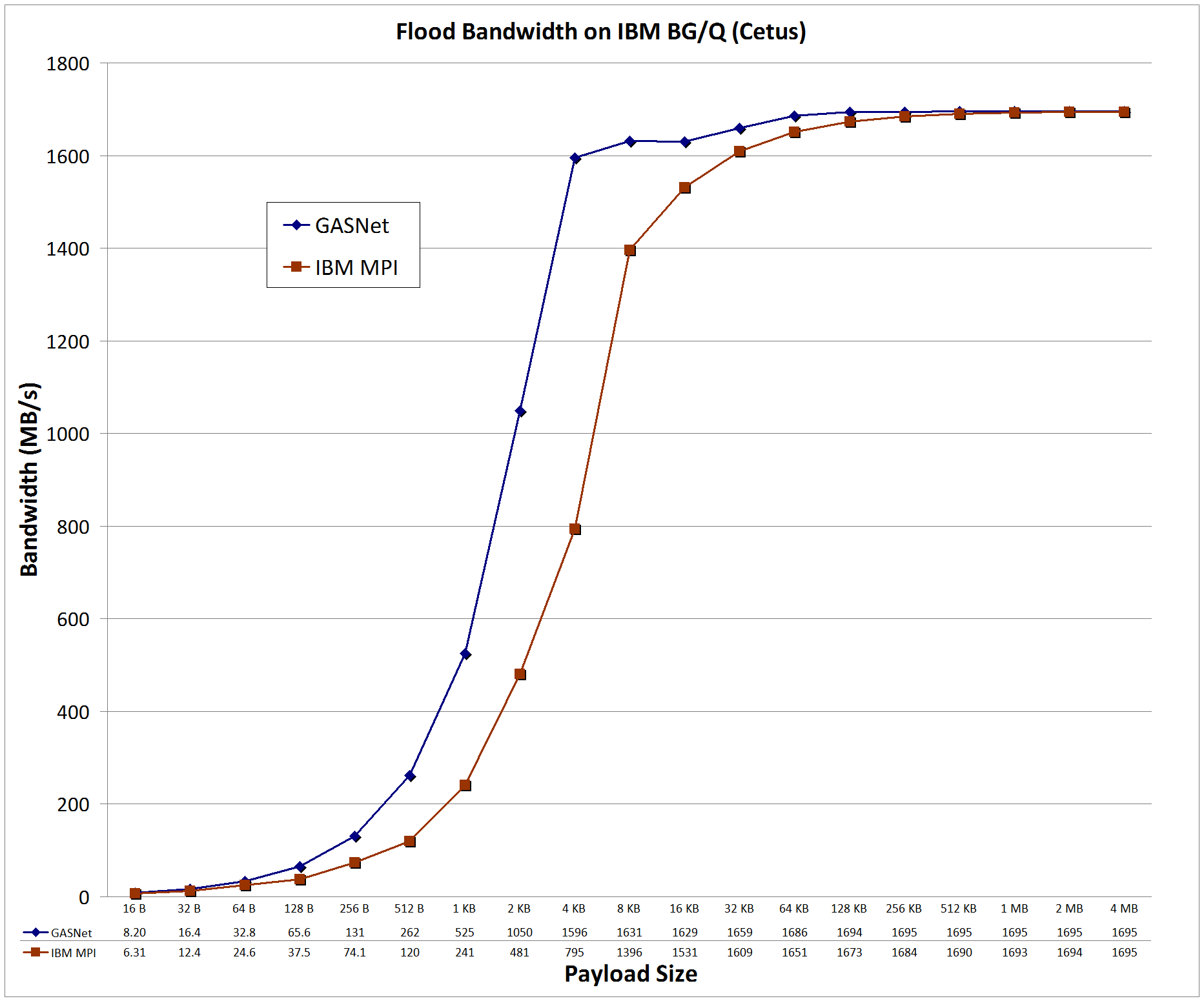
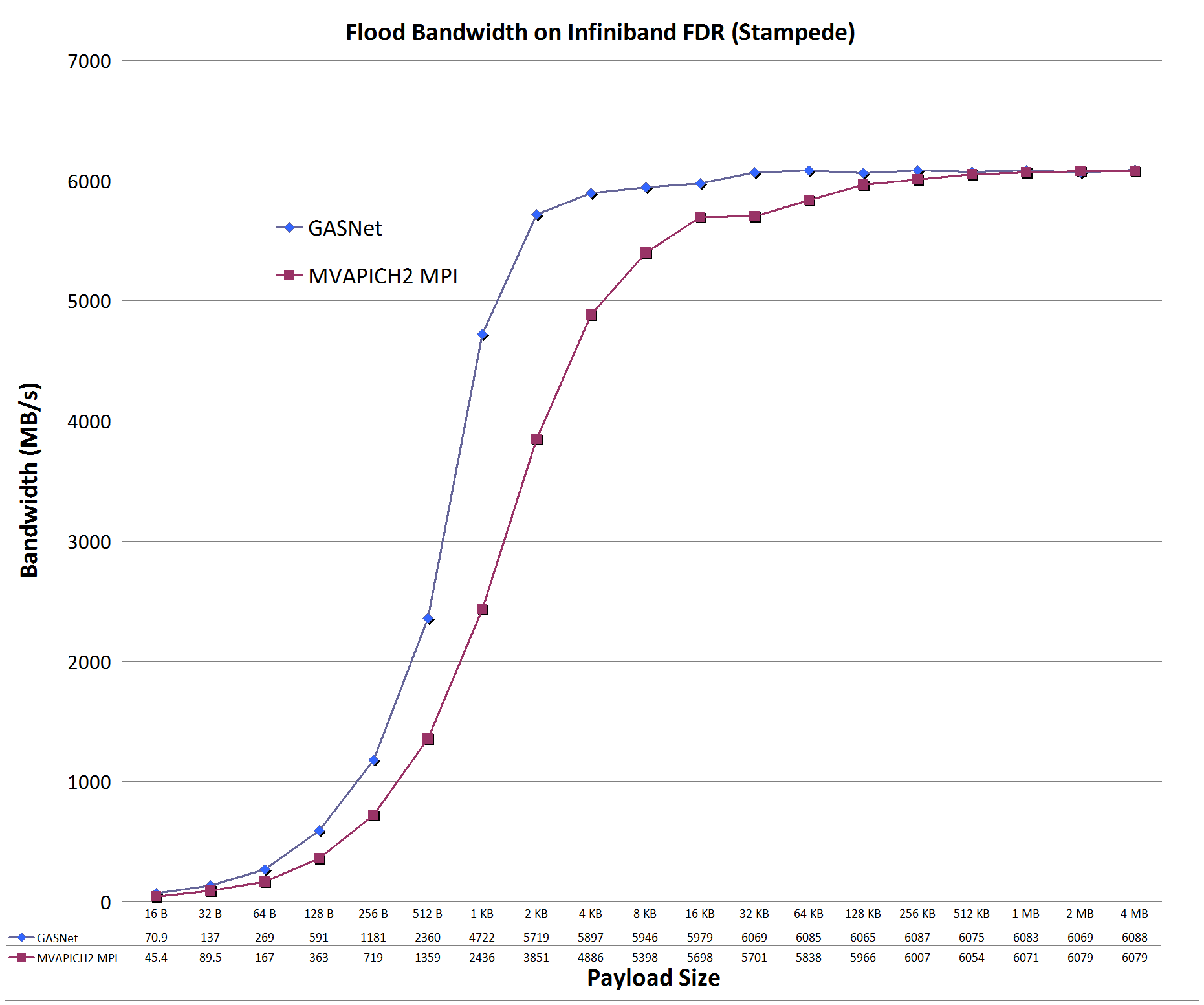
Flood Bandwidth Graphs compare
GASNet testlarge
(uni-directional non-blocking put flood bandwidth) with
OSU's MPI Benchmarks v5.3, test osu_bw (uni-directional Isend/Irecv flood bandwidth).
All bandwidth is reported here in units of Binary Megabytes/sec (MB/sec), where MB = 2^20 bytes (OSU benchmarks default to reporting Decimal MB=1e6).
-
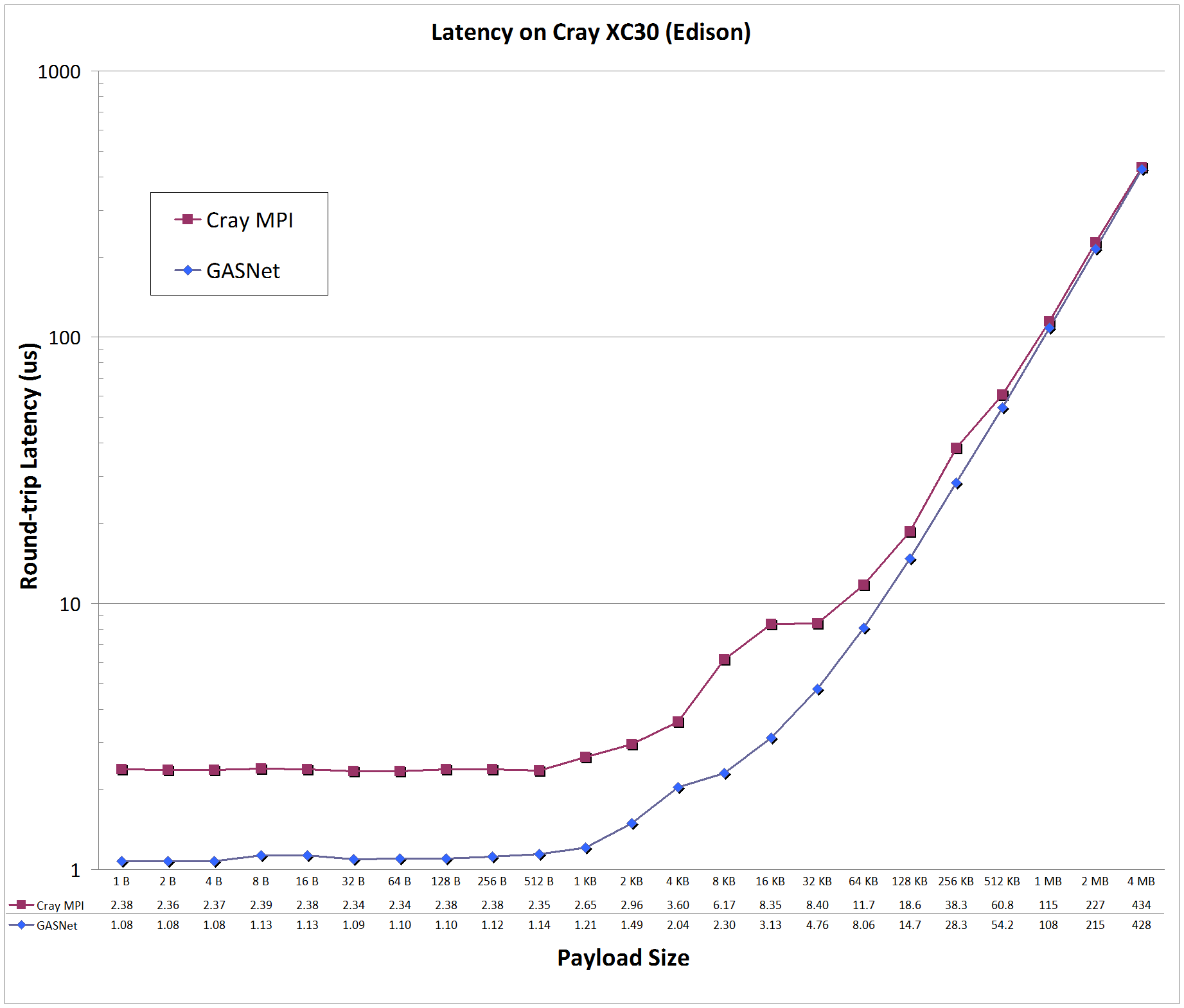
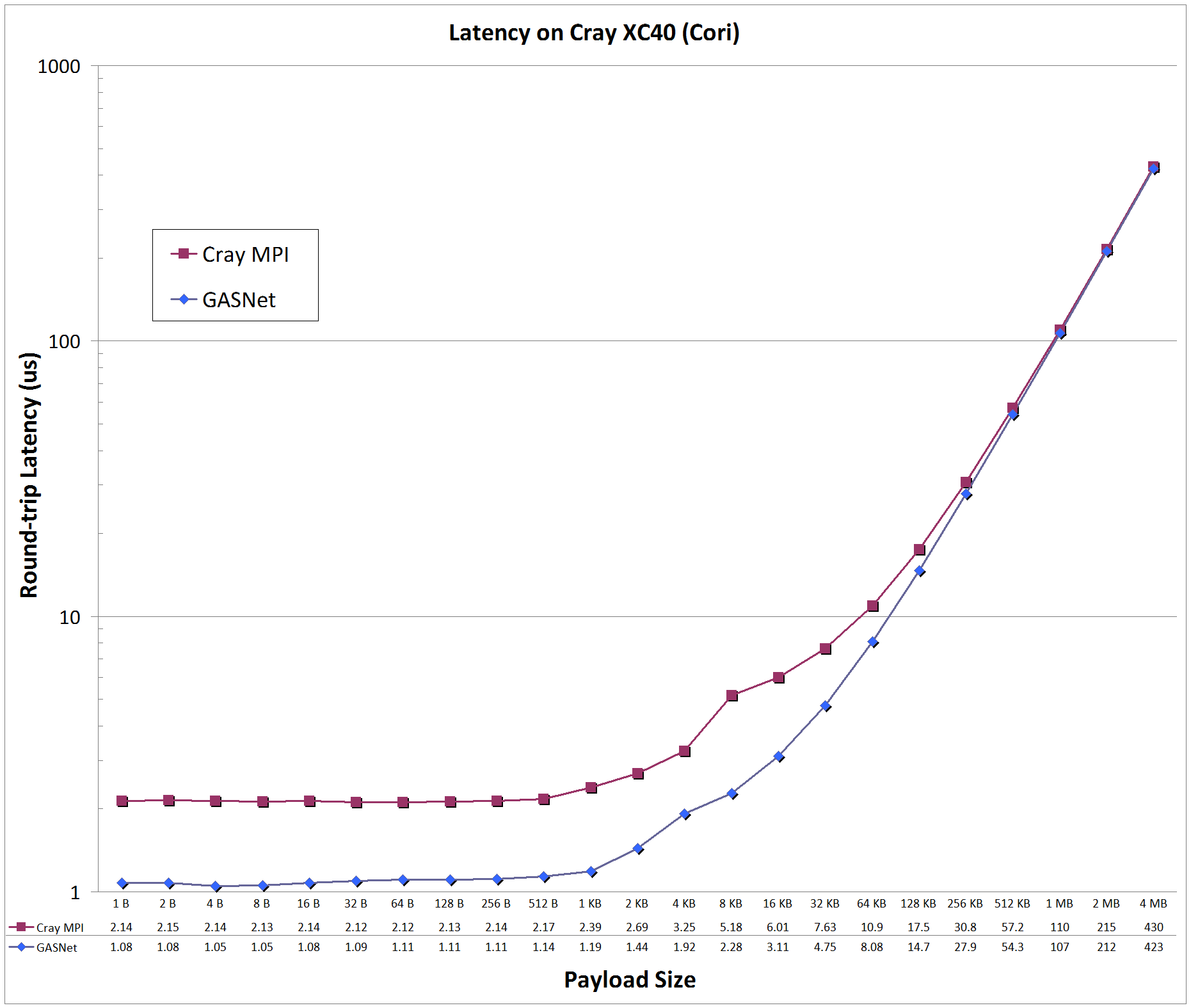
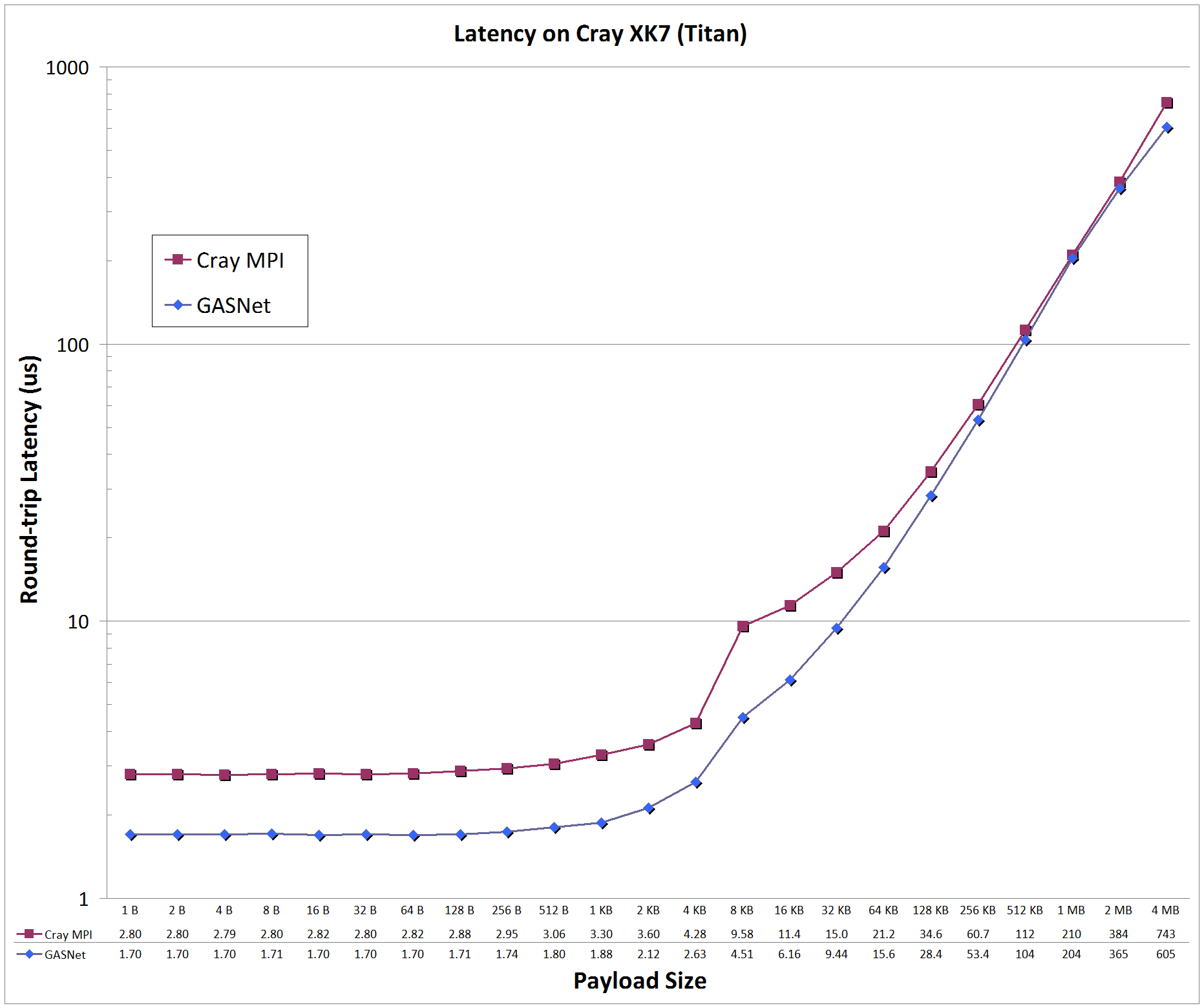
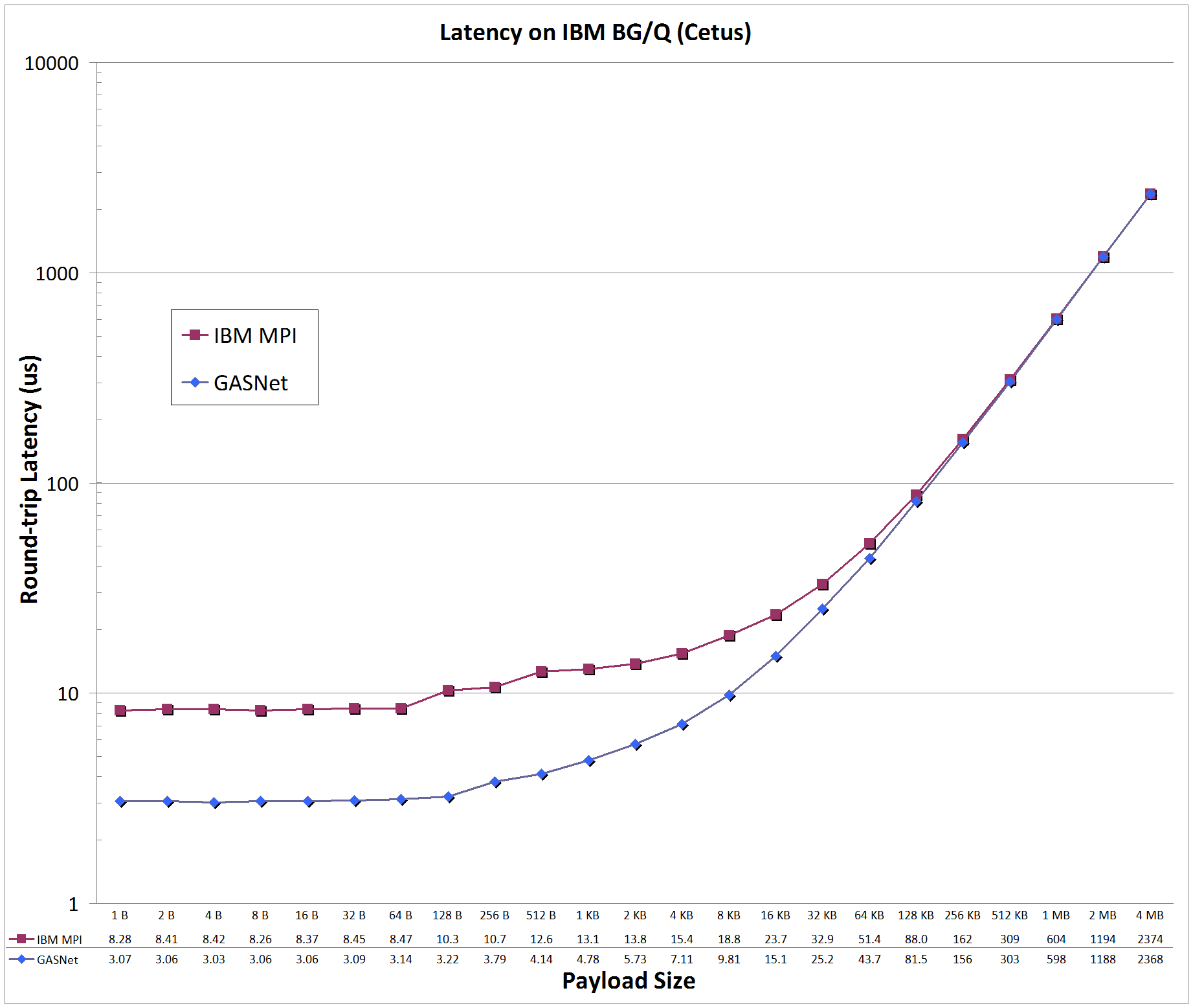
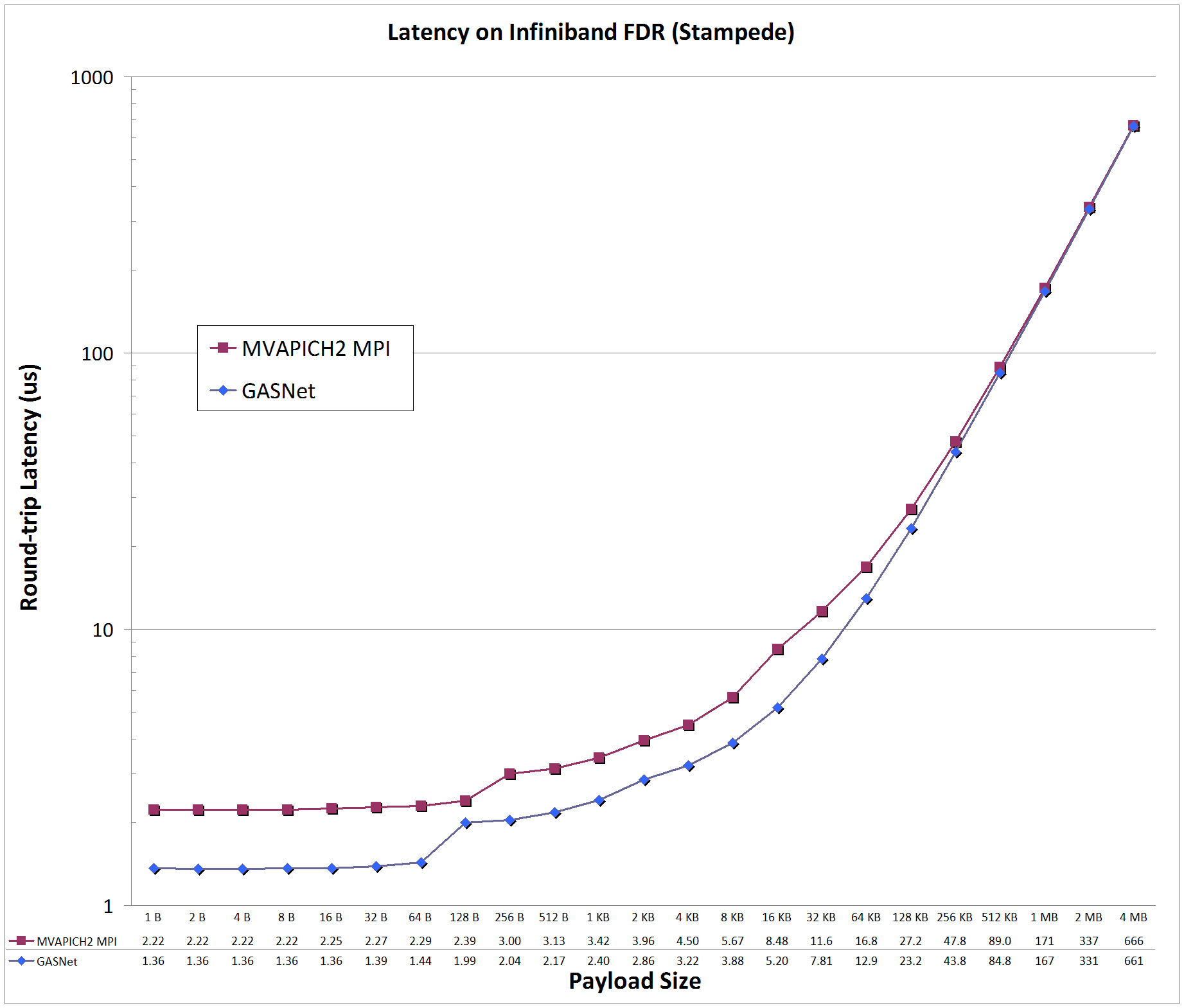
Latency Graphs compare
GASNet testsmall
(uni-directional blocking put latency) with a
slightly modified version
of OSU MPI Benchmark osu_latency (uni-directional Send/Recv ping-pong latency) -
the latter was modified to use a zero-byte acknowledgement to match the uni-directional payload behavior of a PGAS put with a remote completion acknowledgement.
Latency is reported as round-trip time in microseconds (us).
Jump to:
aries-conduit vs MPI: on 'Edison' at NERSC
Edison:
Cray XC30, Cray Aries Interconnect, Node config: 2 x 12-core 2.4 GHz Intel "Ivy Bridge", PE 5.2.56, Cray MPICH 7.4.1
aries-conduit vs MPI: on 'Cori' (Phase I) at NERSC
Cori:
Cray XC40, Cray Aries Interconnect, Node config: 2 x 16-core 2.3 GHz Intel "Haswell", PE 6.0.3, Cray MPICH 7.4.0
gemini-conduit vs MPI: on 'Titan' at Oak Ridge National Laboratory (OLCF)
Titan:
Cray XK7, Cray Gemini Interconnect, Node config: 16-core 2.2 GHz AMD Opteron 6274 (GPUs not used), PE 5.2.82, Cray MPICH 7.2.5
pami-conduit vs MPI: on 'Cetus' at Argonne National Laboratory (ALCF)
Cetus:
IBM BlueGene/Q, Custom interconnect, Node config: 16-core 1.6 GHz PowerPC A2, IBM XLC for BlueGene v12.1, MPICH2 v1.5
ibv-conduit vs MPI: on 'Stampede' at UT Austin Texas Advanced Computing Center (TACC)
Stampede:
Mellanox InfiniBand FDR, Node config: 2 x 8-core 2.7/3.5 GHz Intel Xeon E5-2680 (Xeon Phi co-processor not used), x16 PCIe bus, Intel C 15.0.2, MVAPICH2 2.1 ch3:mrail
Back to the GASNet home page


