GASNet-EX 2023 Performance Examples
The following graphs show performance examples of GASNet-EX release 2023.3.0, measured in April and May 2023.
These graphs were collected following the methodology described in the
following publication, which also contains further discussion of the study and
results:
Bonachea D, Hargrove P.
GASNet-EX: A High-Performance, Portable Communication Library for Exascale,
Proceedings of Languages and Compilers for Parallel Computing (LCPC'18). Oct 2018.
doi:10.25344/S4QP4W.
Test Methodology:
All tests use two physical nodes, with one core injecting communication
operations to the remote node and all other cores idle. Results have been
collected using the default MPI implementation on each system, provided by
the system vendor.
Software and hardware configuration details are provided in each section.
The graphs which follow are comprised of series from the following
microbenchmarks:
-
GASNet-EX RMA (Put and Get) results report the output of
testlarge and testsmall, provided as part of the 2023.3.0
source distribution.
-
MPI RMA (Put and Get) results report the output of the
Unidir_put and Unidir_get subtests from the IMB-RMA
portion of the
Intel Benchmarks (IMB),
v2021.3 (the latest available version at the time the results were gathered).
These subtests measure the performance of MPI_Put() and
MPI_Get() in a passive-target access epoch synchronized with
MPI_Win_flush().
-
MPI message-passing (Isend/Irecv) results report the output of the
Uniband subtest from the IMB-MPI1 portion of the
Intel Benchmarks (IMB), v2021.3.
For each system tested, there are two graphs measuring different
aspects of network performance:
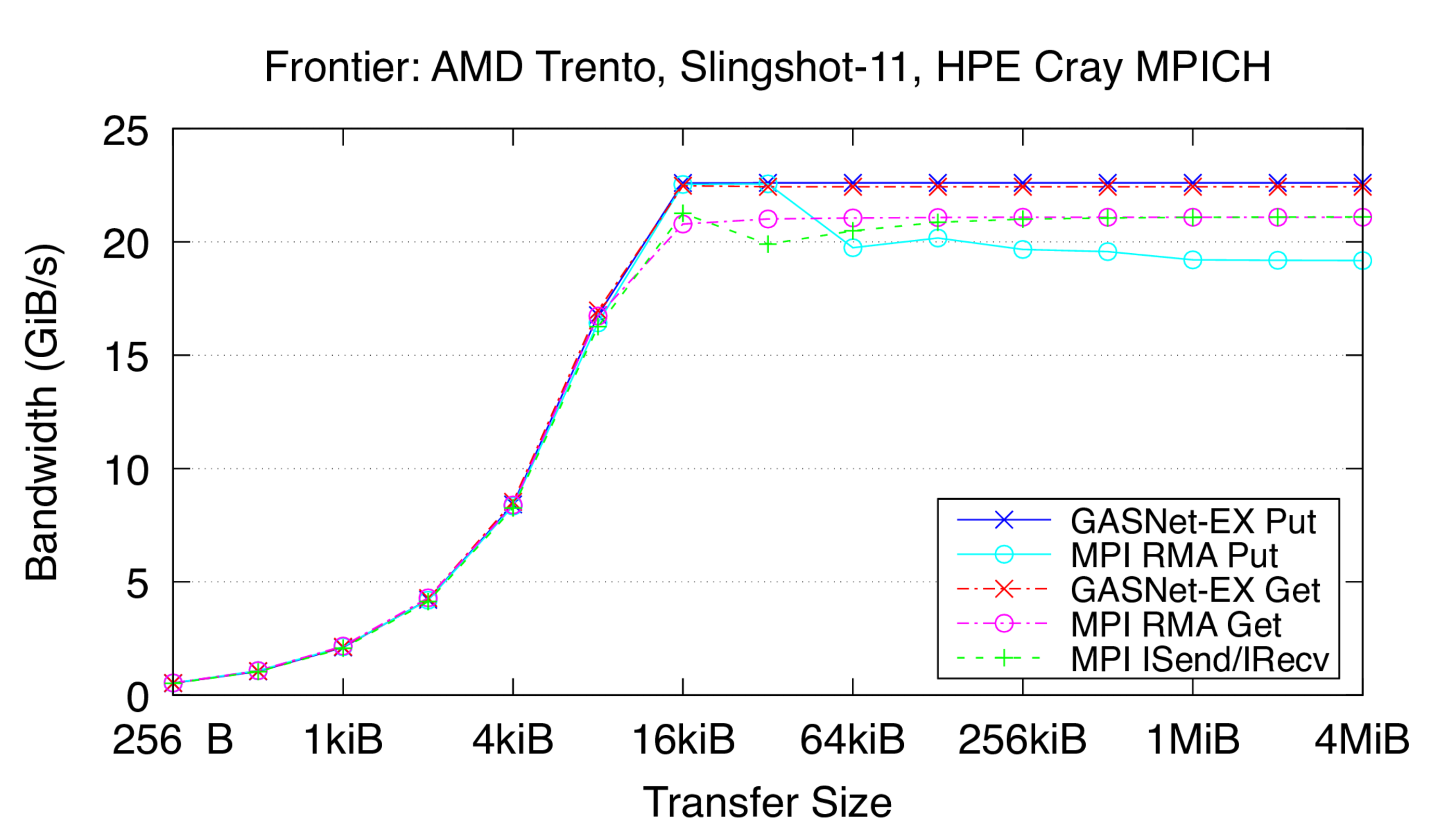
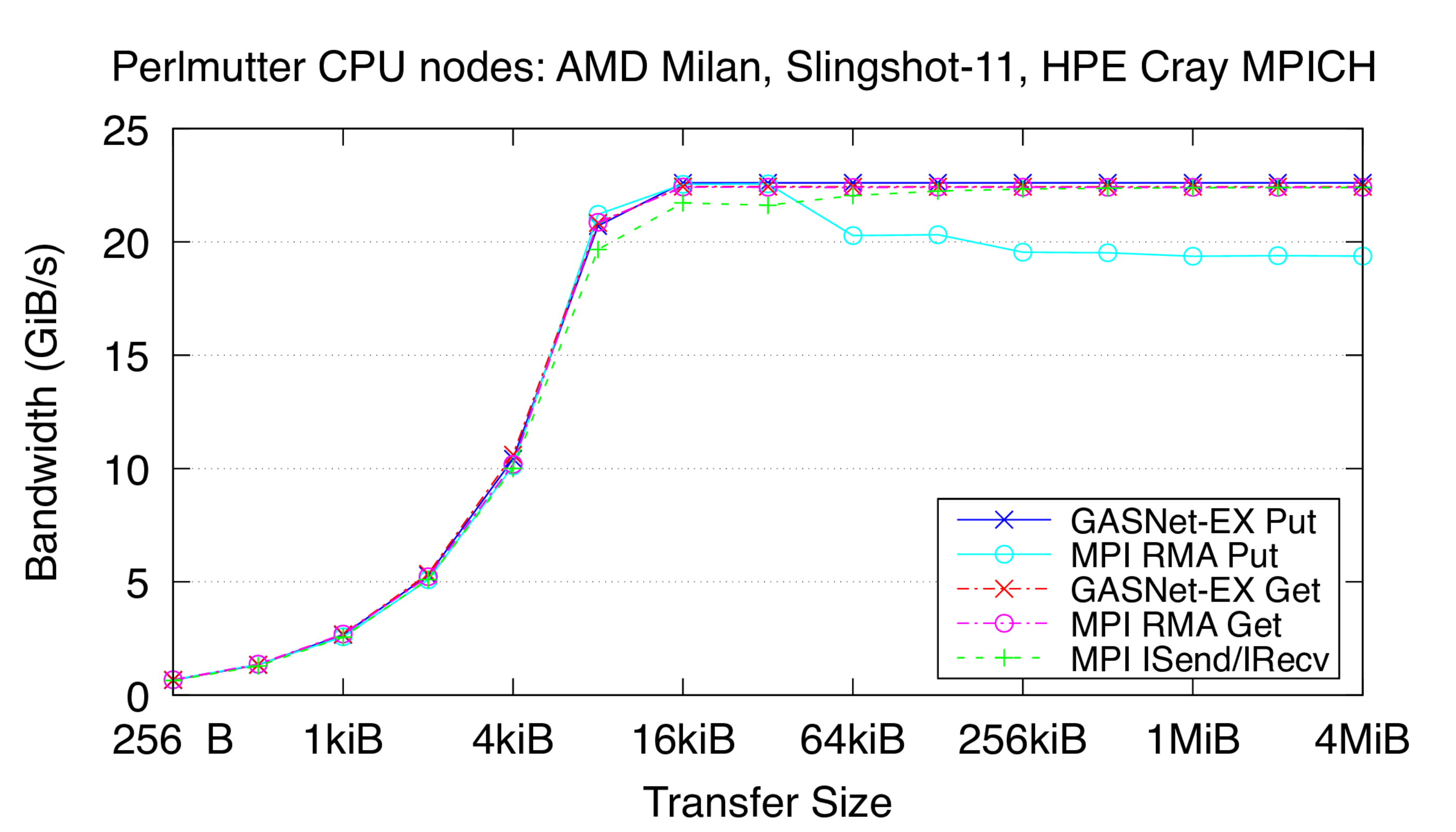
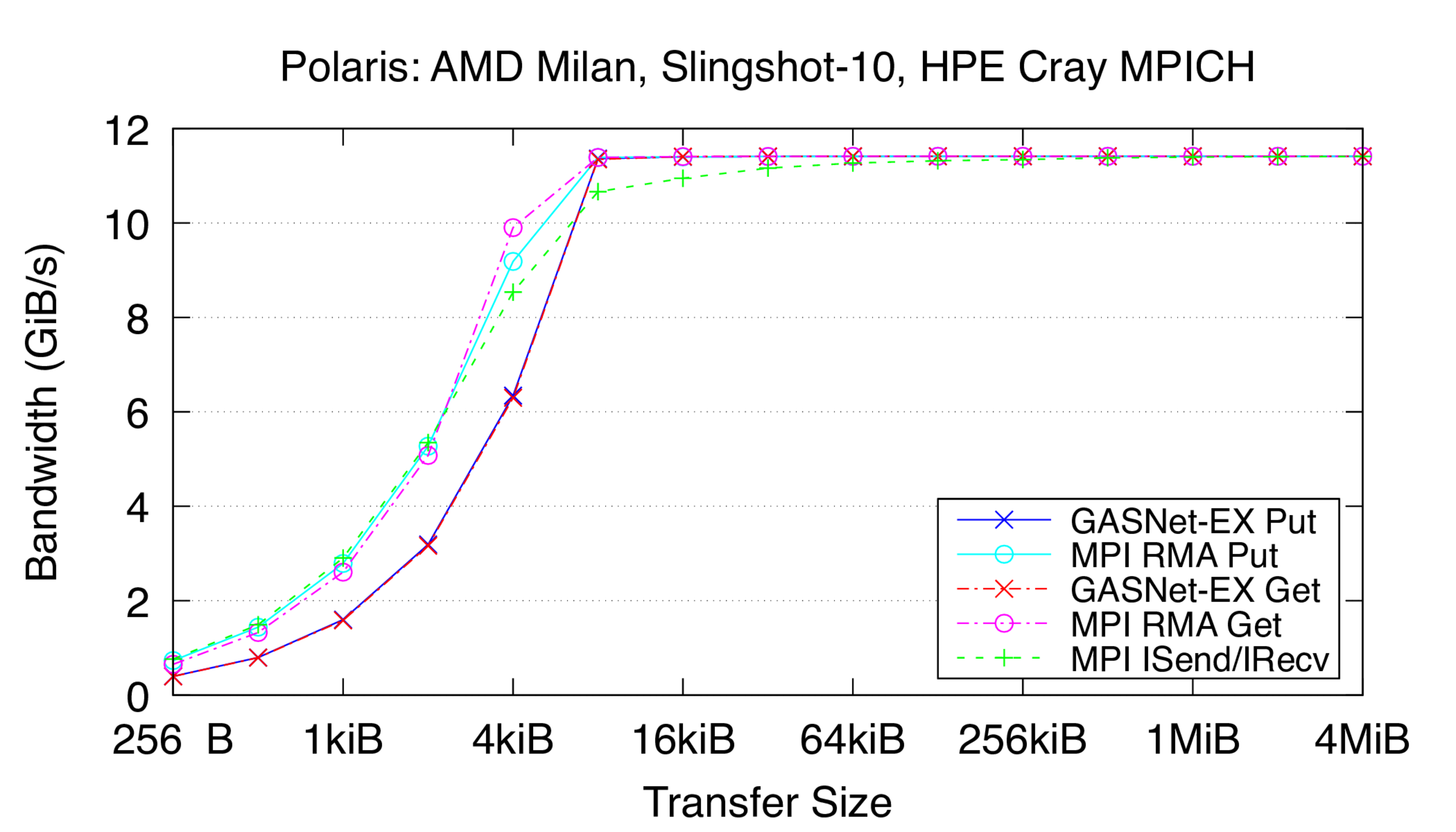
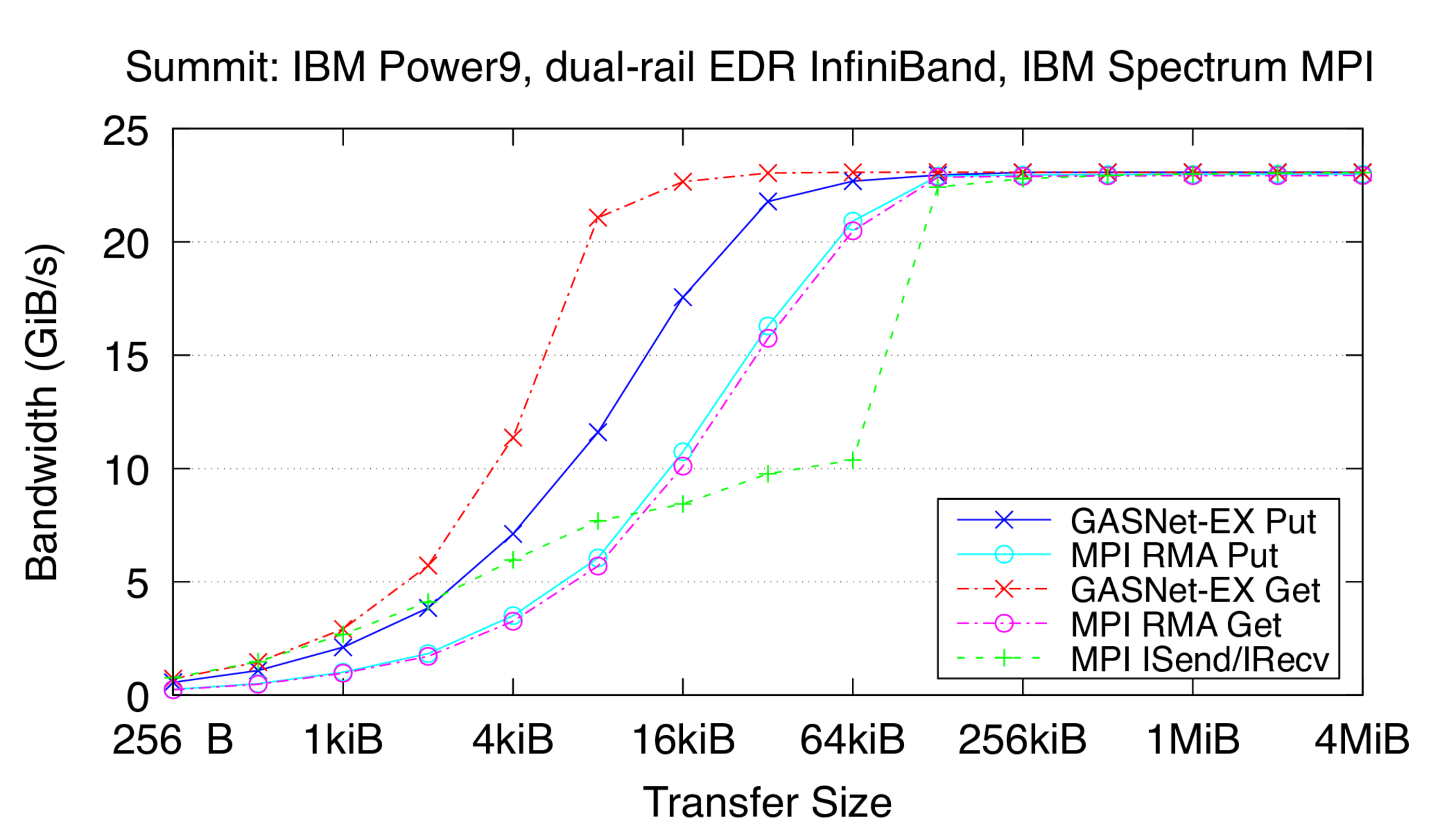
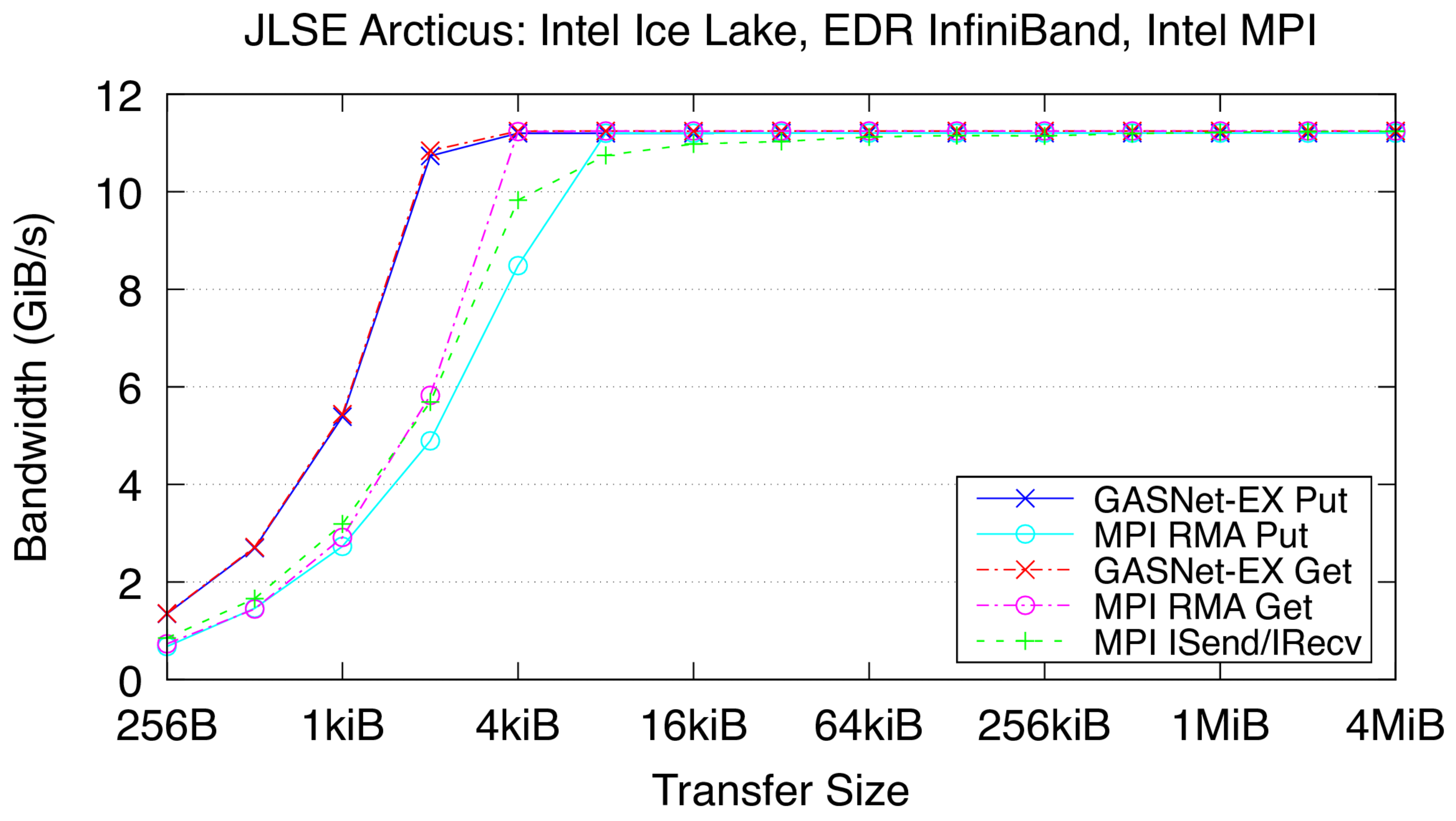
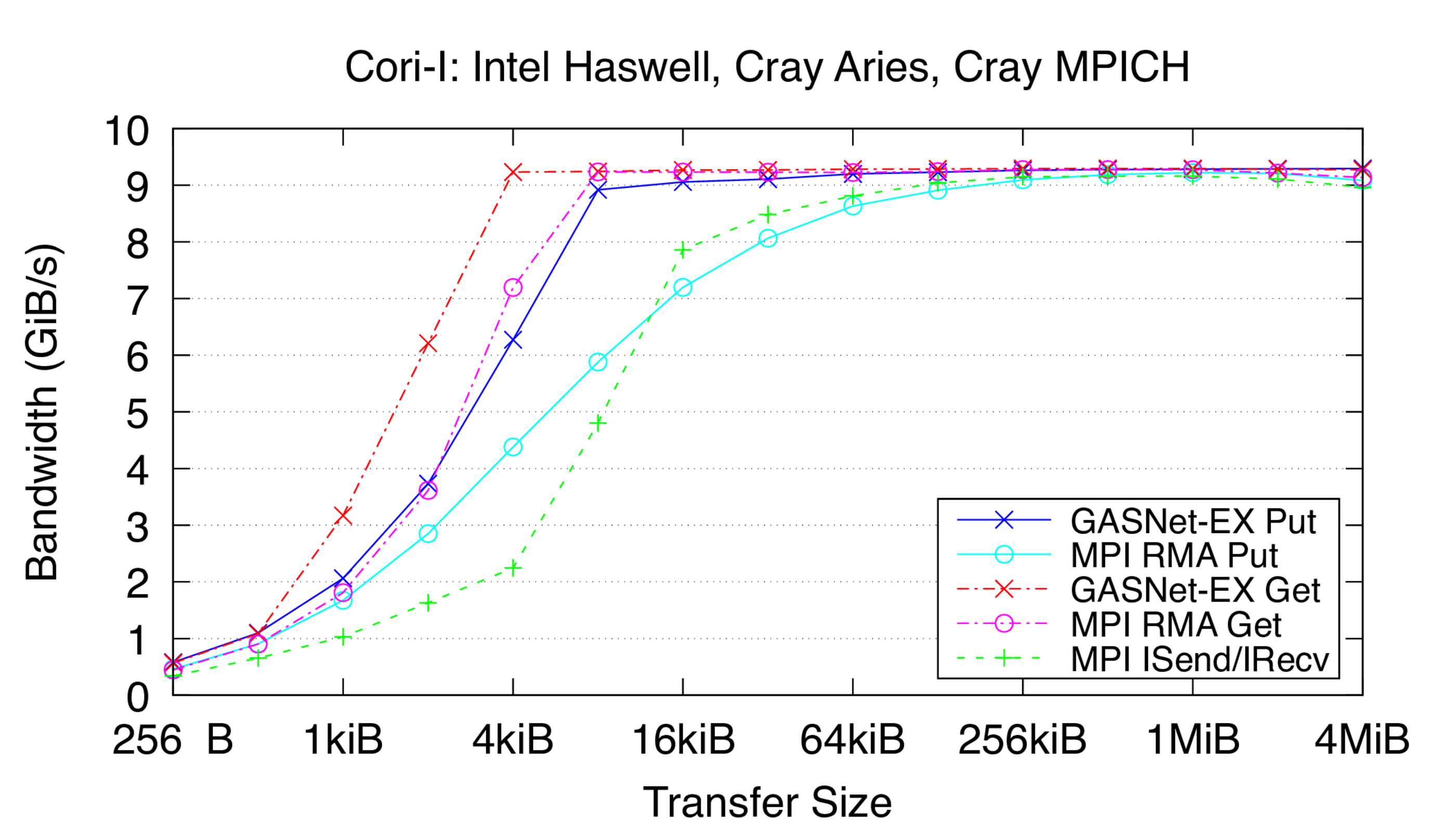
-
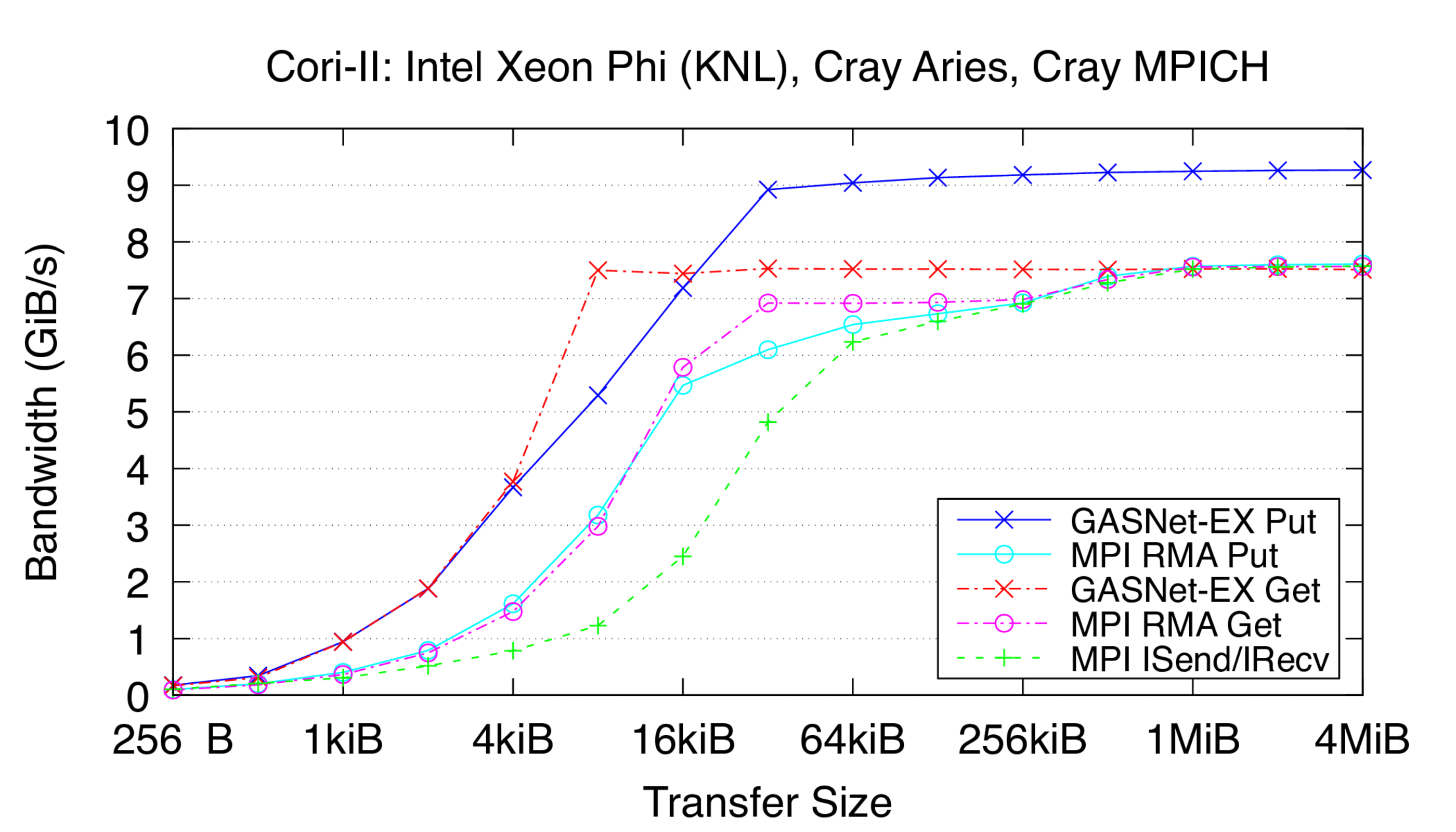
Flood Bandwidth Graphs show uni-directional non-blocking flood
bandwidth, and compare GASNet-EX testlarge with the "MODE: AGGREGATE"
bandwidth reports of the Unidir_put and Unidir_get subtests
and the bandwidth report of the Uniband subtest.
All bandwidth is reported here in units of Binary Gigabytes/sec (GiB/sec),
where GiB = 230 bytes (GASNet-EX tests report Binary Megabytes
(MB=220) while IMB tests report Decimal Megabytes
(MB=106)).
Command lines used:
- [mpirun -np 2] testlarge -m -in [iters] 4194304 B
- [mpirun -np 2] IMB-RMA -time 600 -iter_policy off -iter [iters] -msglog 4:22 Unidir_put
- [mpirun -np 2] IMB-RMA -time 600 -iter_policy off -iter [iters] -msglog 4:22 Unidir_get
- [mpirun -np 2] IMB-MPI1 -time 600 -iter_policy off -iter [iters] -msglog 4:22 Uniband
-
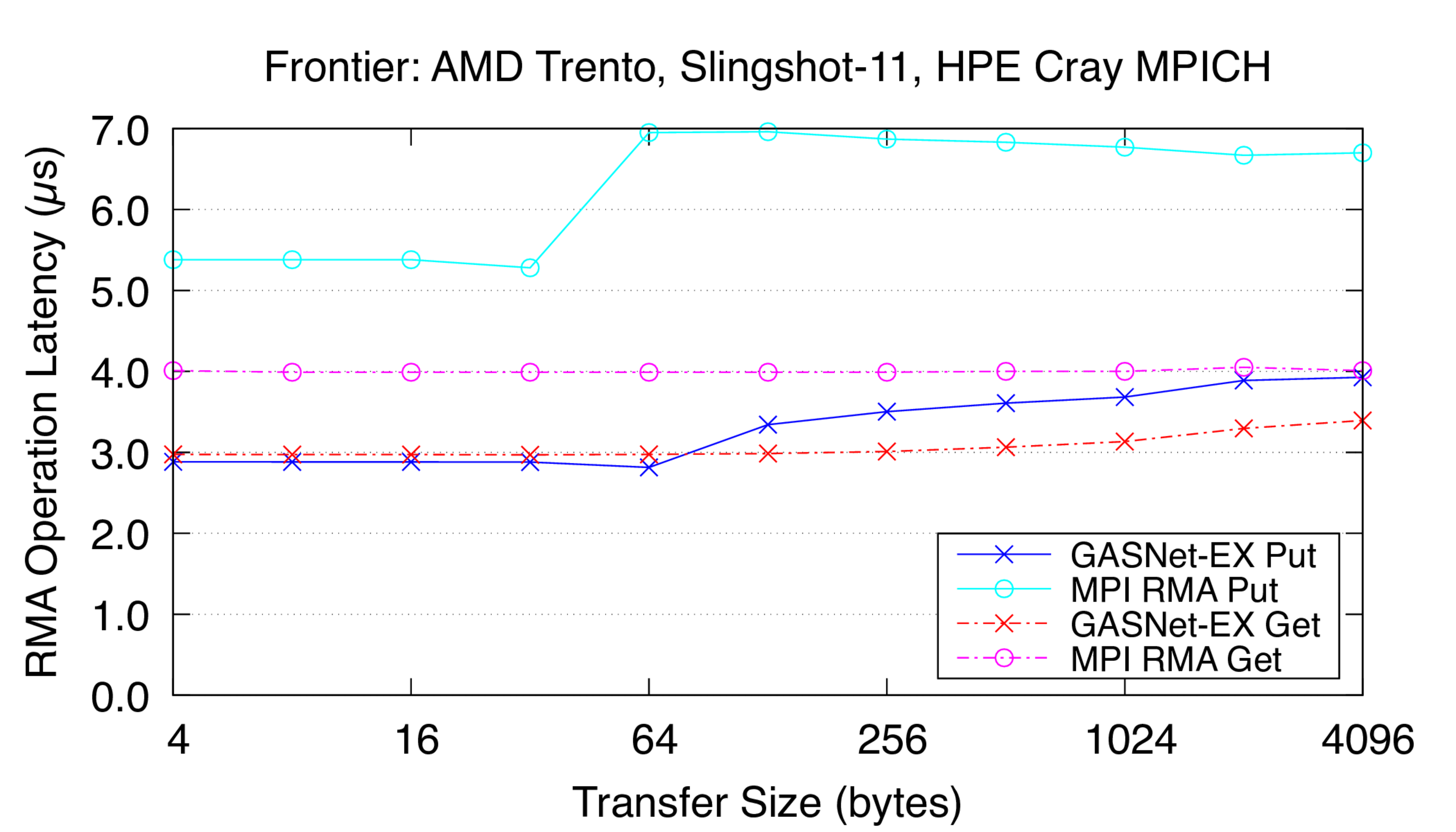
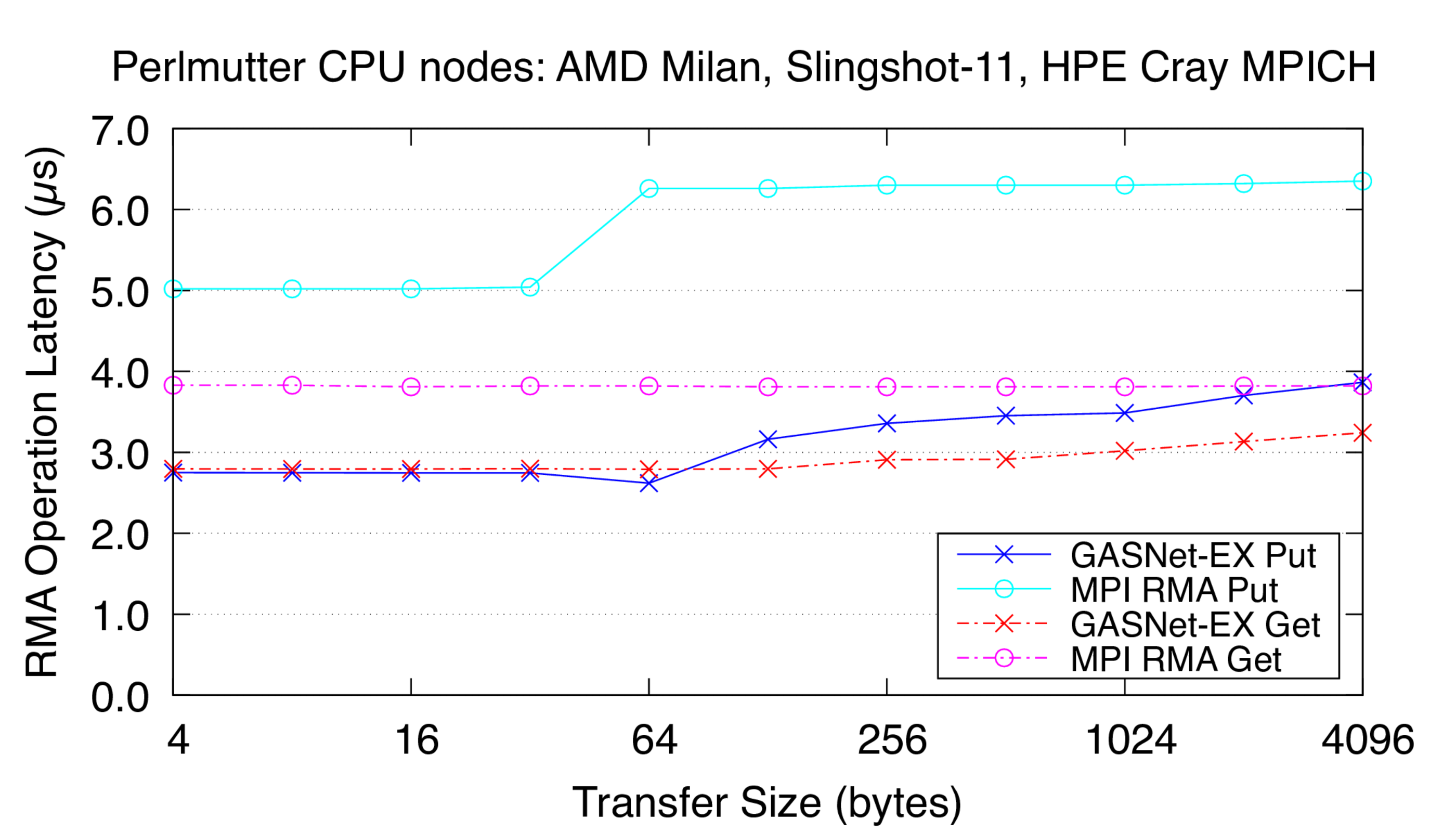
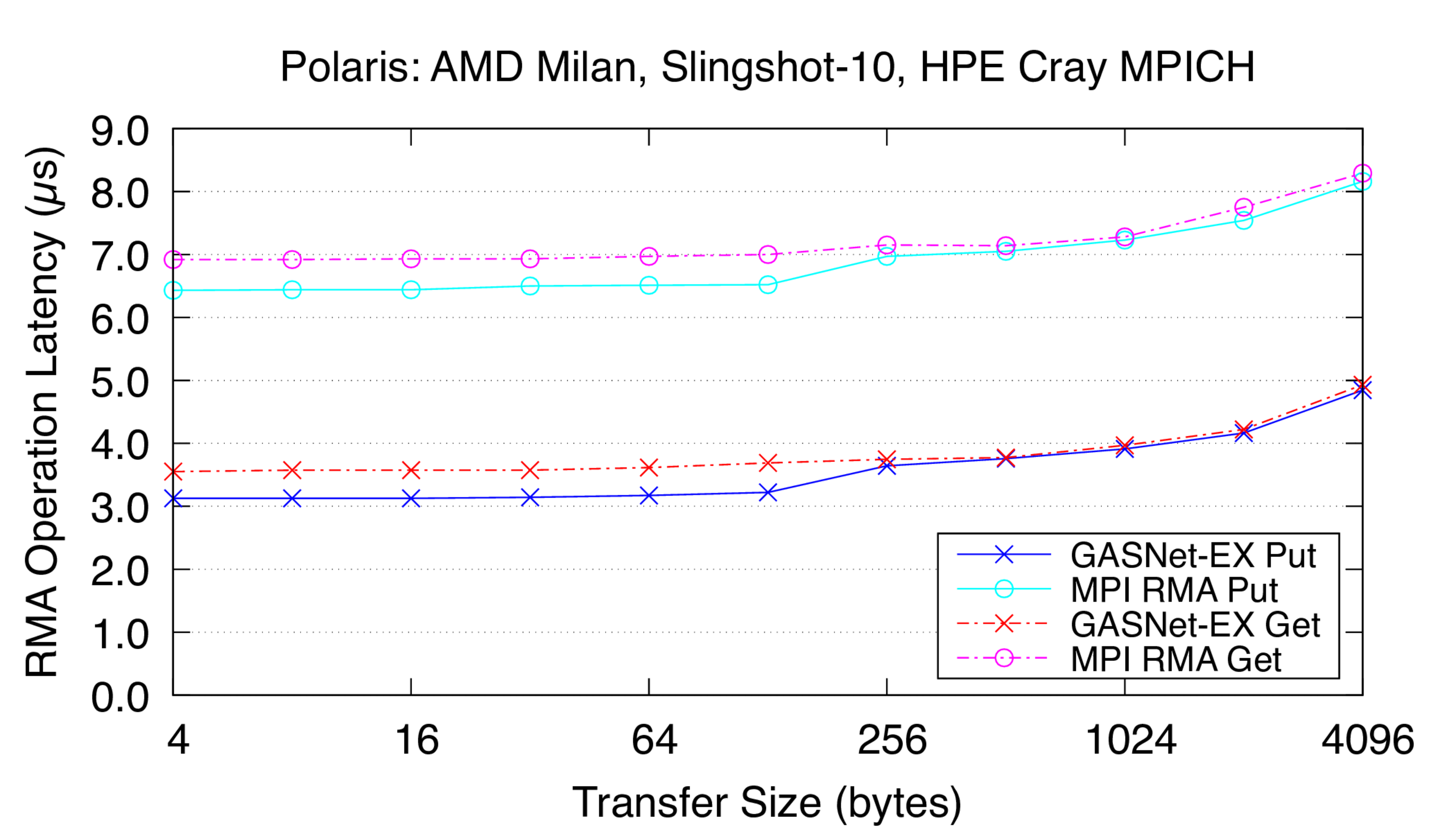
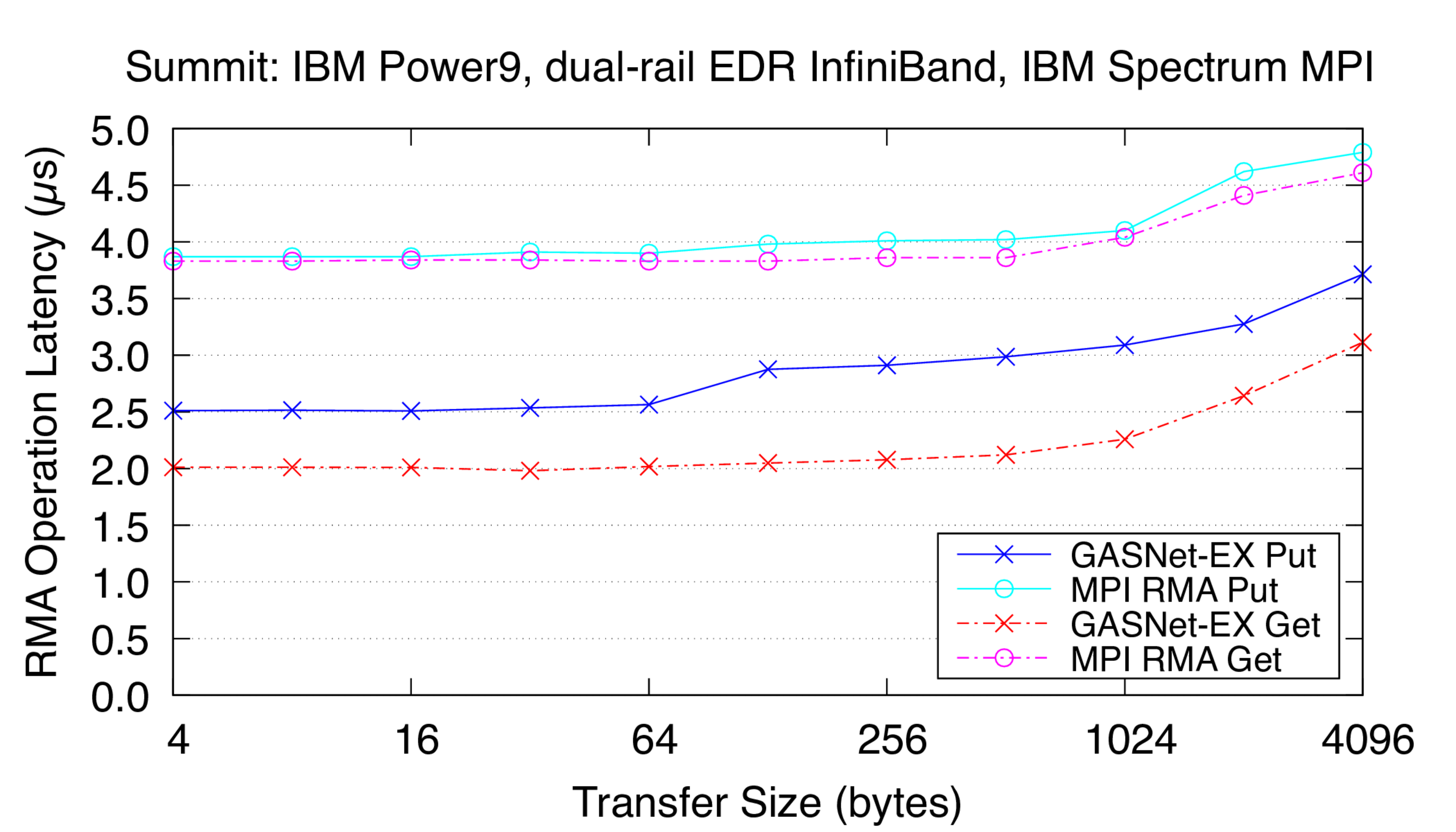
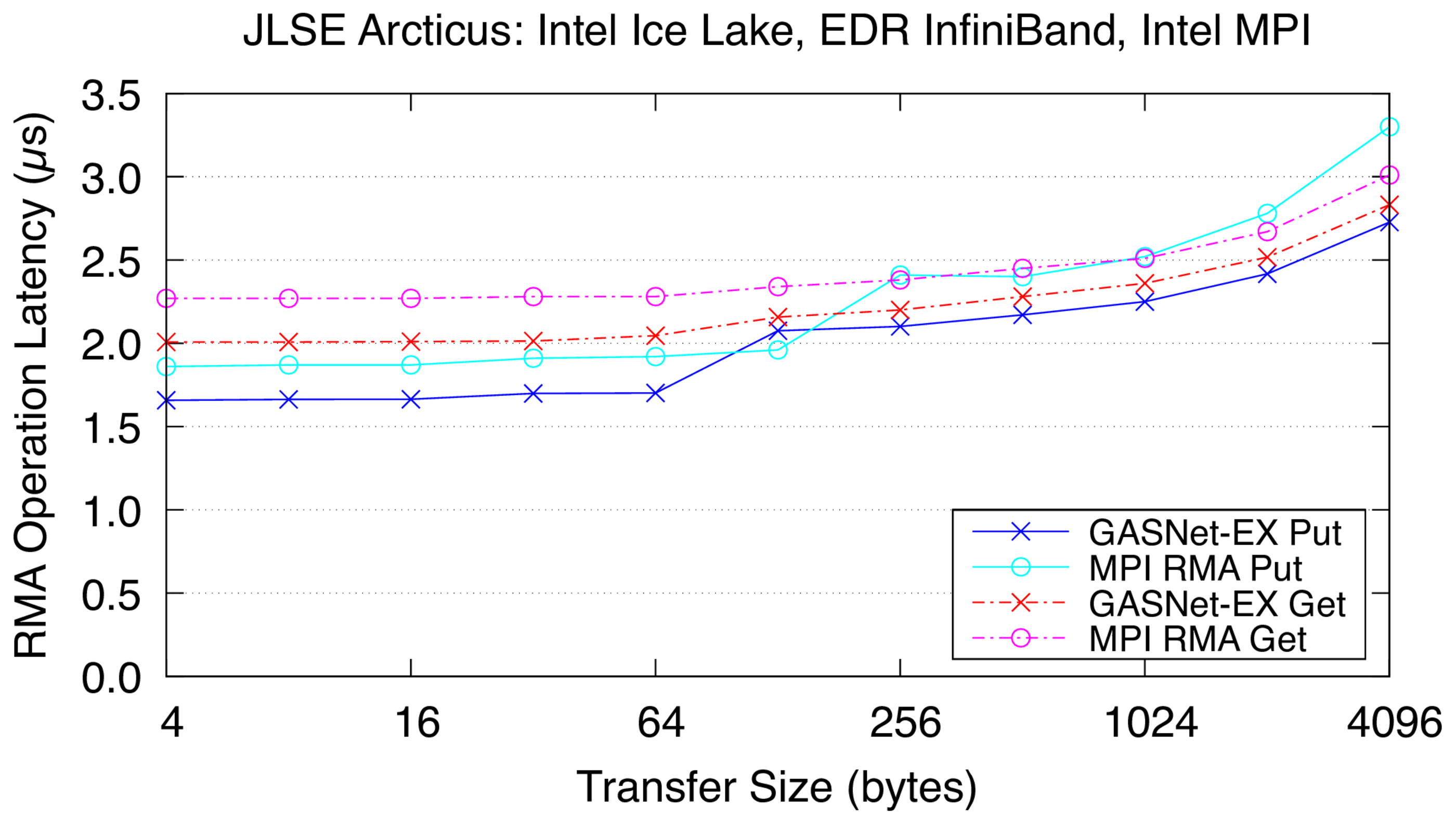
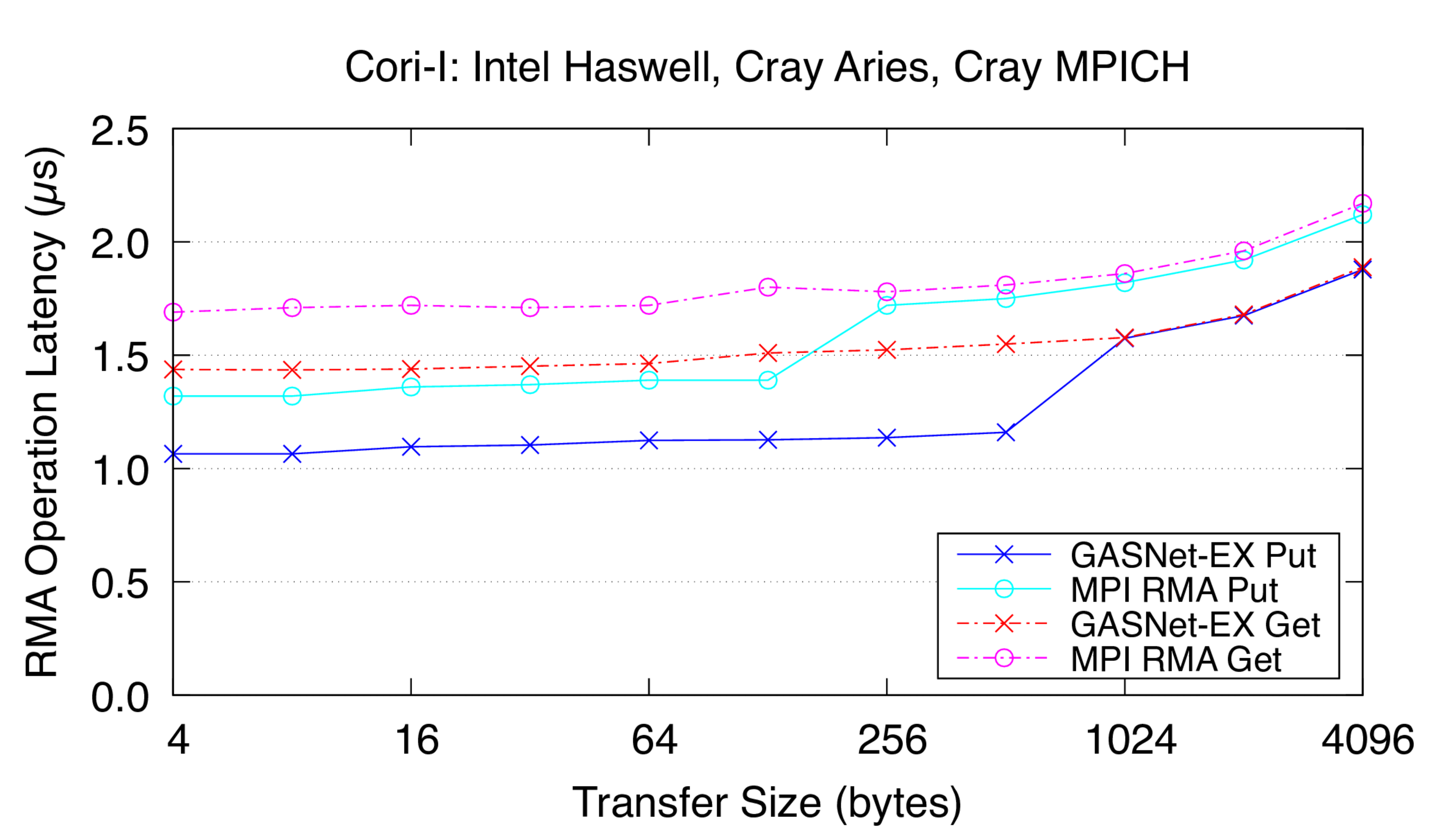
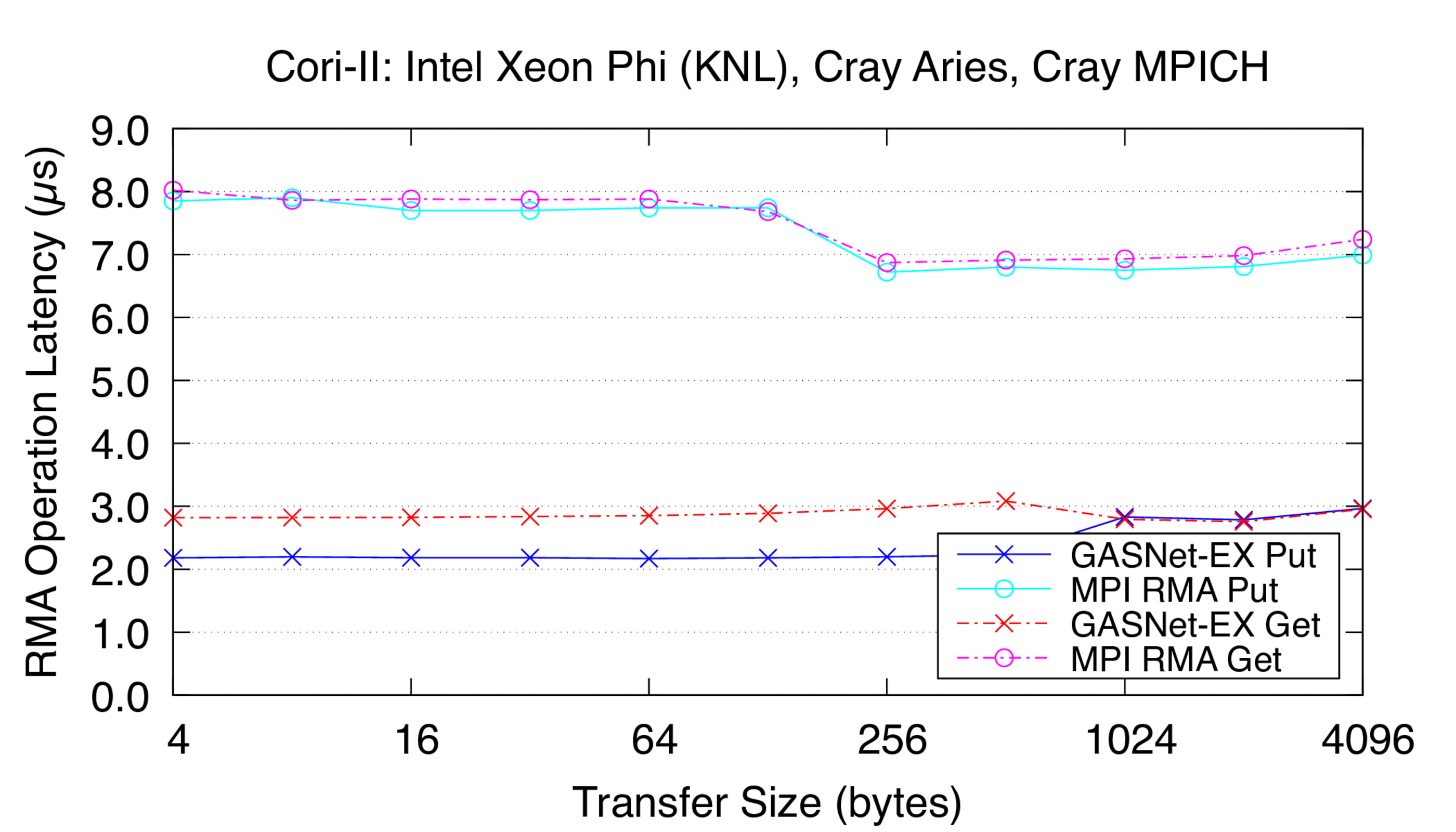
Latency Graphs show uni-directional blocking operation latency, and
compare GASNet-EX testsmall with the "MODE: NON-AGGREGATE" latency
reports of Unidir_put and Unidir_get subtests.
Latency is reported as total operation completion time (i.e. a
wire-level round-trip) in microseconds (μs).
Command lines used:
- [mpirun -np 2] testsmall -m -in [iters] 4096 A
- [mpirun -np 2] IMB-RMA -time 600 -iter_policy off -iter [iters] -msglog 2:12 Unidir_put
- [mpirun -np 2] IMB-RMA -time 600 -iter_policy off -iter [iters] -msglog 2:12 Unidir_get
Jump to:
ofi-conduit vs HPE Cray MPI: on 'Frontier' at OLCF (Slingshot-11 network)
Frontier:
HPE Cray EX, Slingshot-11 Interconnect,
Node config: 64-core 2 GHz AMD EPYC "Trento" 7453s, PE 8.3.3, GNU C 12.2.0, Cray MPICH 8.1.23, libfabric 1.15.2.0
These are results for a single Slingshot-11 NIC per process.
ofi-conduit vs HPE Cray MPI: on 'Perlmutter' CPU nodes at NERSC (Slingshot-11 network)
Perlmutter:
HPE Cray EX, Slingshot-11 Interconnect,
Node config:
2x 64-core AMD EPYC "Milan" 7763, PE 8.3.3, GNU C 11.2.0, Cray MPICH 8.1.25, libfabric 1.15.2.0
These are results for a single Slingshot-11 NIC per process.
ofi-conduit vs HPE Cray MPI: on 'Polaris' at ALCF (Slingshot-10 network)
Polaris:
HPE Cray EX, Slingshot-10 Interconnect,
Node config: 32-core 2.8 GHz AMD EPYC "Milan" 7543p, PE 8.3.3, GNU C 11.2.0, Cray MPICH 8.1.16, libfabric 1.11.0.4.125
These are results for a single Slingshot-10 NIC per process.
ibv-conduit vs IBM Spectrum MPI: on 'Summit' at OLCF (EDR InfiniBand network)
Summit:
Mellanox EDR InfiniBand,
Node config: 2 x 22-core 3.8 GHz IBM POWER9, Red Hat Linux 8.2, GNU C 9.1.0, IBM Spectrum MPI 10.4.0.3-20210112
ibv-conduit vs Intel MPI: on 'Articus' at JLSE (EDR InfiniBand network)
Arcticus:
Mellanox EDR InfiniBand,
Node config: 2 x 24-core 2.4 GHz Intel "Sky Lake", openSUSE Leap 15.4, GNU C 7.5.0, Intel MPI 2021.8.0
aries-conduit vs Cray MPI: on 'Cori (Phase-I)' at NERSC (Aries network)
Cori-I:
Cray XC40, Cray Aries Interconnect,
Node config: 2 x 16-core 2.3 GHz Intel "Haswell", PE 6.0.10, Intel C 19.1.2.254, Cray MPICH 7.7.19
aries-conduit vs Cray MPI: on 'Cori (Phase-II)' at NERSC (Aries network)
Cori-II:
Cray XC40, Cray Aries Interconnect,
Node config: 68-core 1.4 GHz Intel Xeon Phi "Knights Landing", PE 6.0.10, Intel C 19.1.2.254, Cray MPICH 7.7.19
Older results also available:
This research was funded in part by the Exascale Computing Project
(17-SC-20-SC), a collaborative effort of the U.S. Department of Energy Office
of Science and the National Nuclear Security Administration.
This research used resources of the National Energy Research Scientific
Computing Center (NERSC), a U.S. Department of Energy Office of Science User
Facility located at Lawrence Berkeley National Laboratory, operated under
Contract No. DE-AC02-05CH11231 using NERSC award DDR-ERCAP0023595.
This research used resources of the Argonne Leadership Computing Facility,
which is a DOE Office of Science User Facility supported under Contract
DE-AC02-06CH11357.
This research used resources of the Oak Ridge Leadership Computing Facility
at the Oak Ridge National Laboratory, which is supported by the Office of
Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725.
We gratefully acknowledge the computing resources provided and operated by
the Joint Laboratory for System Evaluation (JLSE) at Argonne National
Laboratory.
Back to the GASNet home page


